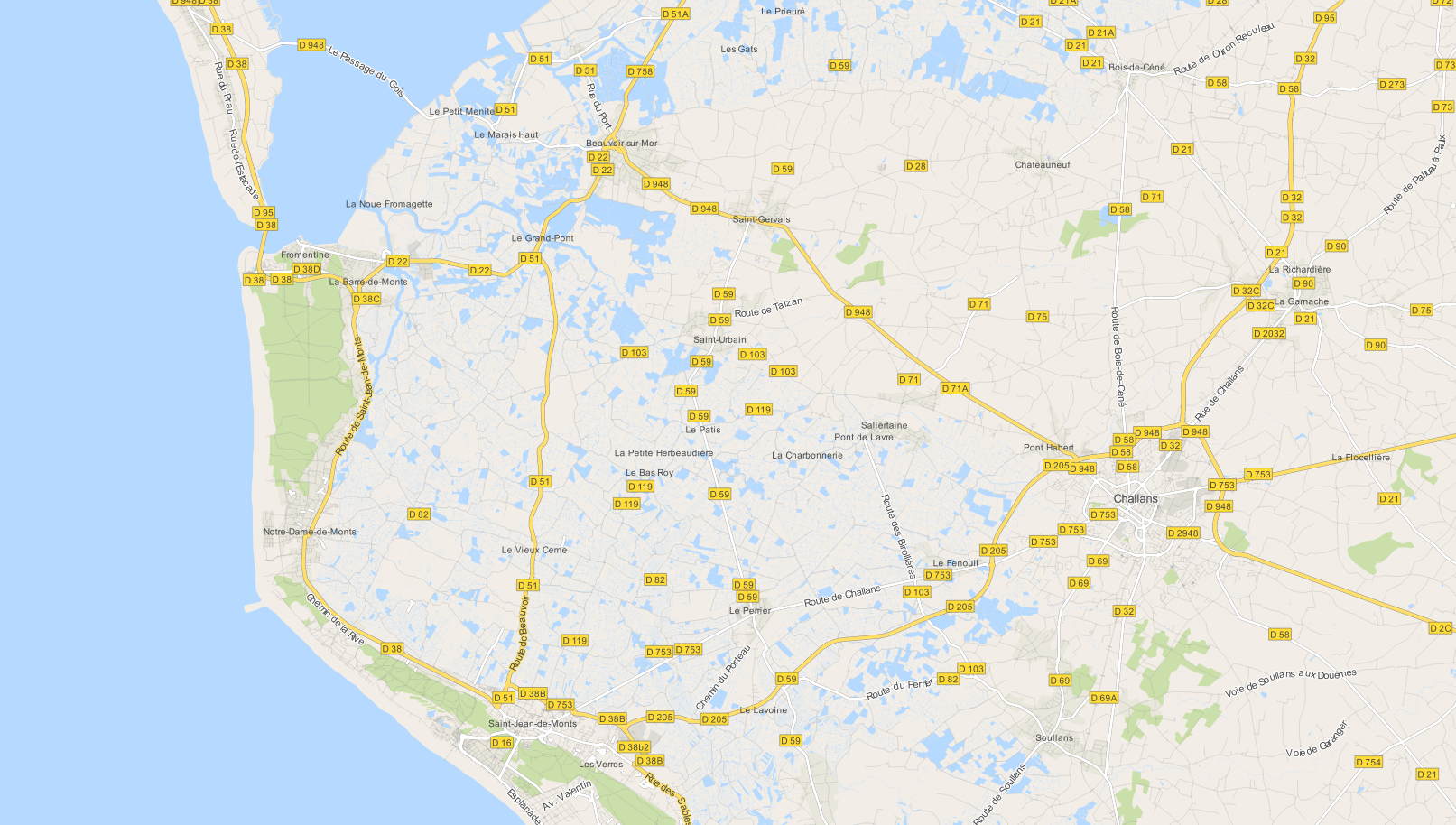
Using OSM data in QGIS is a hot topic but so far, no best practices for downloading, preprocessing and styling the data have been established. There are many potential solutions with all their advantages and disadvantages. To give you a place to start, I thought I’d share a workflow which works for me to create maps like the following one from nothing but OSM:

Getting the data
Raw OSM files can be quite huge. That’s why it’s definitely preferable to download the compressed binary .pbf format instead of the XML .osm format.
As a download source, I’d recommend Geofabrik. The area in the example used in this post is part of the region Pays de la Loire, France.
Preparing the data for QGIS
In the preprocessing step, we will extract our area of interest and convert the .pbf into a spatialite database which can be used directly in QGIS.
This can be done in one step using ogr2ogr:
C:\Users\anita_000\Geodata\OSM_Noirmoutier>ogr2ogr -f "SQLite" -dsco SPATIALITE=YES -spat 2.59 46.58 -1.44 47.07 noirmoutier.db noirmoutier.pbf
where the -spat option controls the area of interest to be extracted.
When I first published this post, I suggested a two step approach. You can find it here for future reference:
For the first step: extracting the area of interest, we need Osmosis. (For Windows, you can get osmosis from openstreetmap.org. Unpack to use. Requires Java.)
When you have Osmosis ready, we can extract the area of interest to the .osm format:
C:\Users\anita_000\Geodata\OSM_Noirmoutier>..\bin\osmosis.bat --read-pbf pays-de-la-loire-latest.osm.pbf --bounding-box left=-2.59 bottom=46.58 right=-1.44 top=47.07 --write-xml noirmoutier.osm
While QGIS can also load .osm files, I found that performance and access to attributes is much improved if the .osm file is converted to spatialite. Luckily, that’s easy using ogr2ogr:
C:\Users\anita_000\Geodata\OSM_Noirmoutier>ogr2ogr -f "SQLite" -dsco SPATIALITE=YES noirmoutier.db noirmoutier.osm
Finishing preprocessing in QGIS
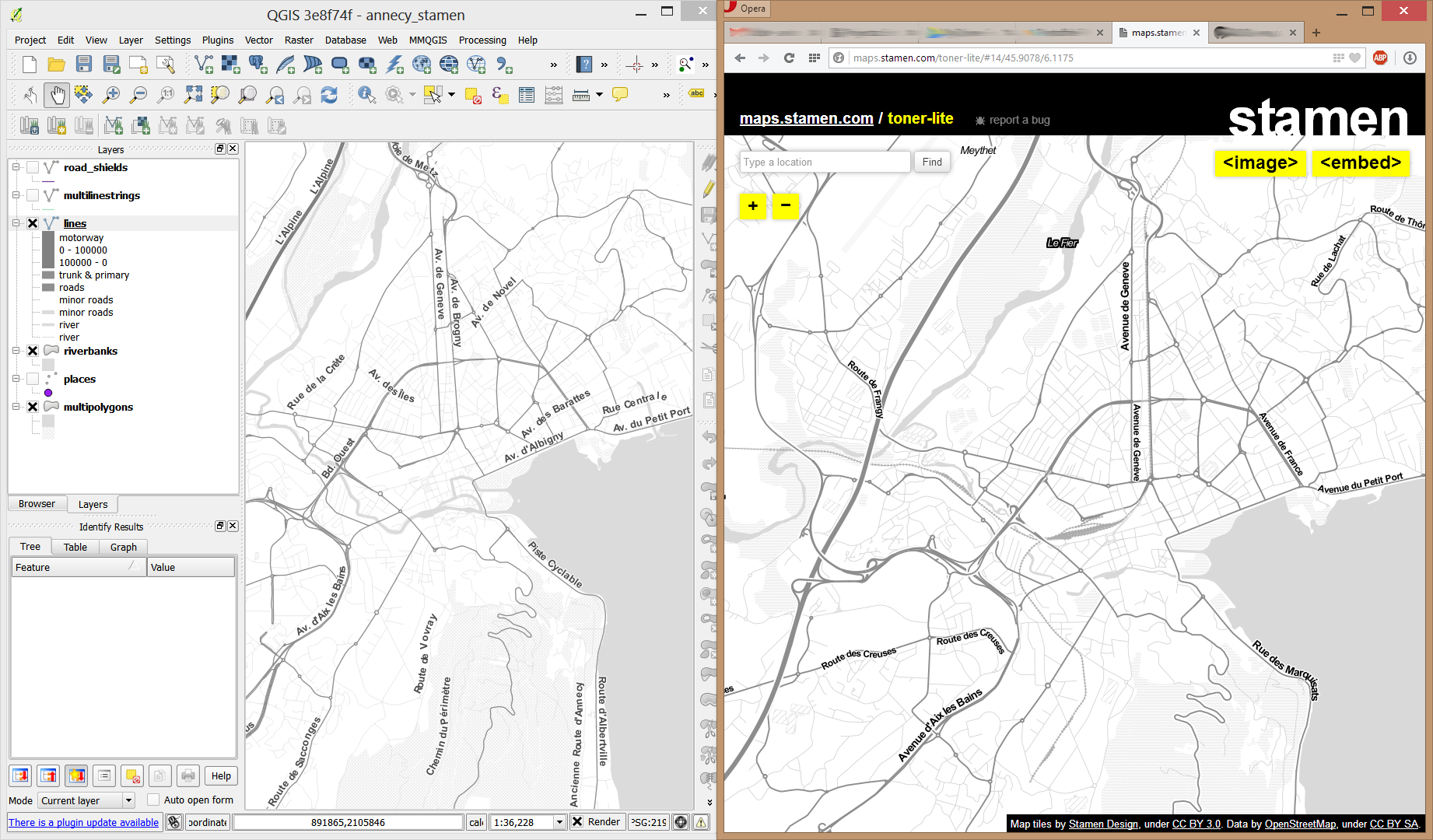
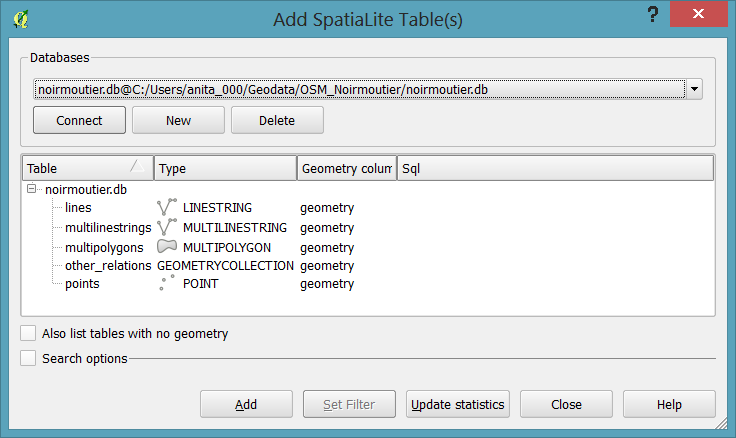
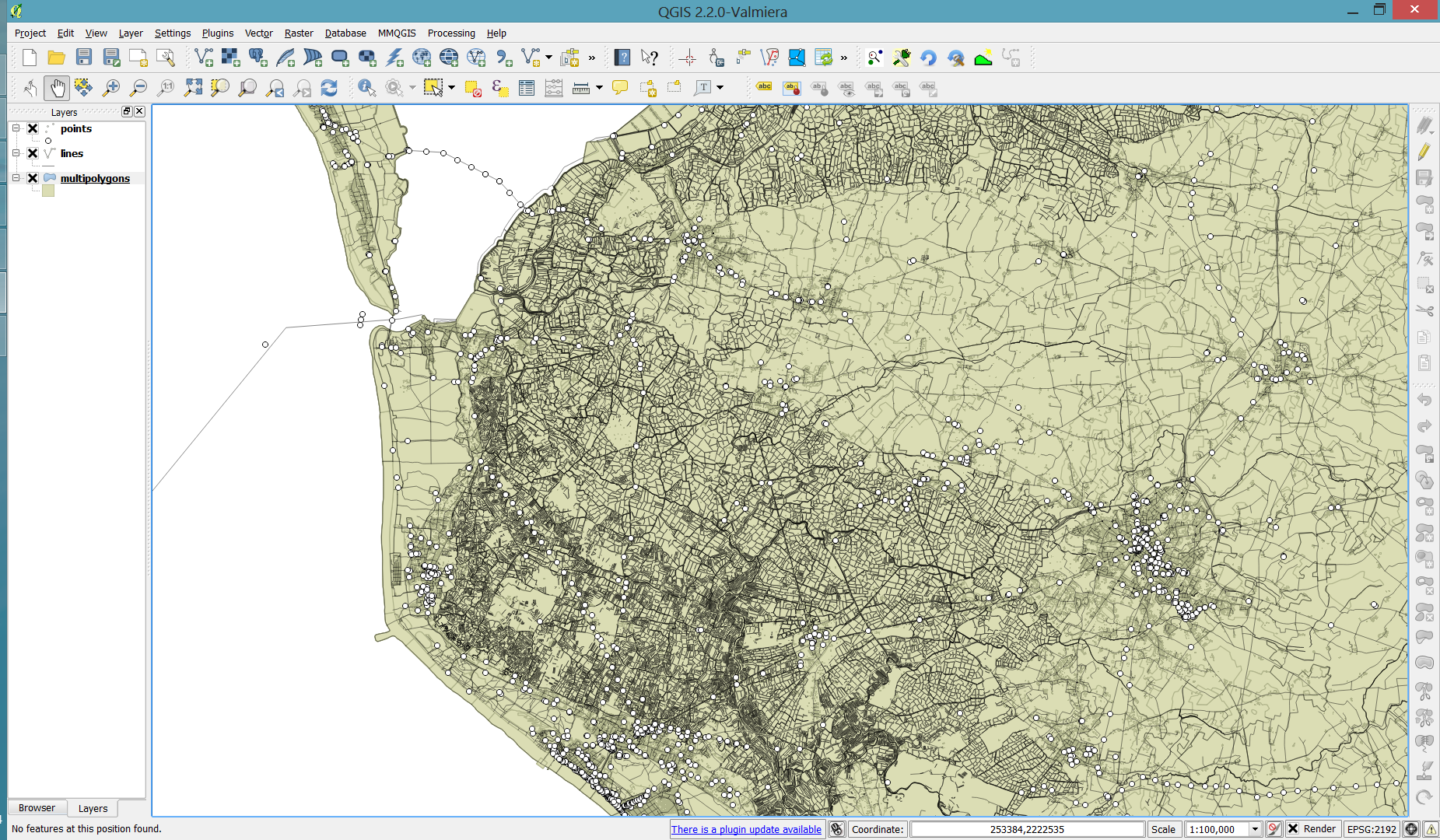
In QGIS, we’ll want to load the points, lines, and multipolygons using Add SpatiaLite Layer:

When we load the spatialite tables, there are a lot of features and some issues:
- There is no land polygon. Instead, there are “coastline” line features.
- Most river polygons are missing. Instead there are “riverbank” line features.

Luckily, creating the missing river polygons is not a big deal:
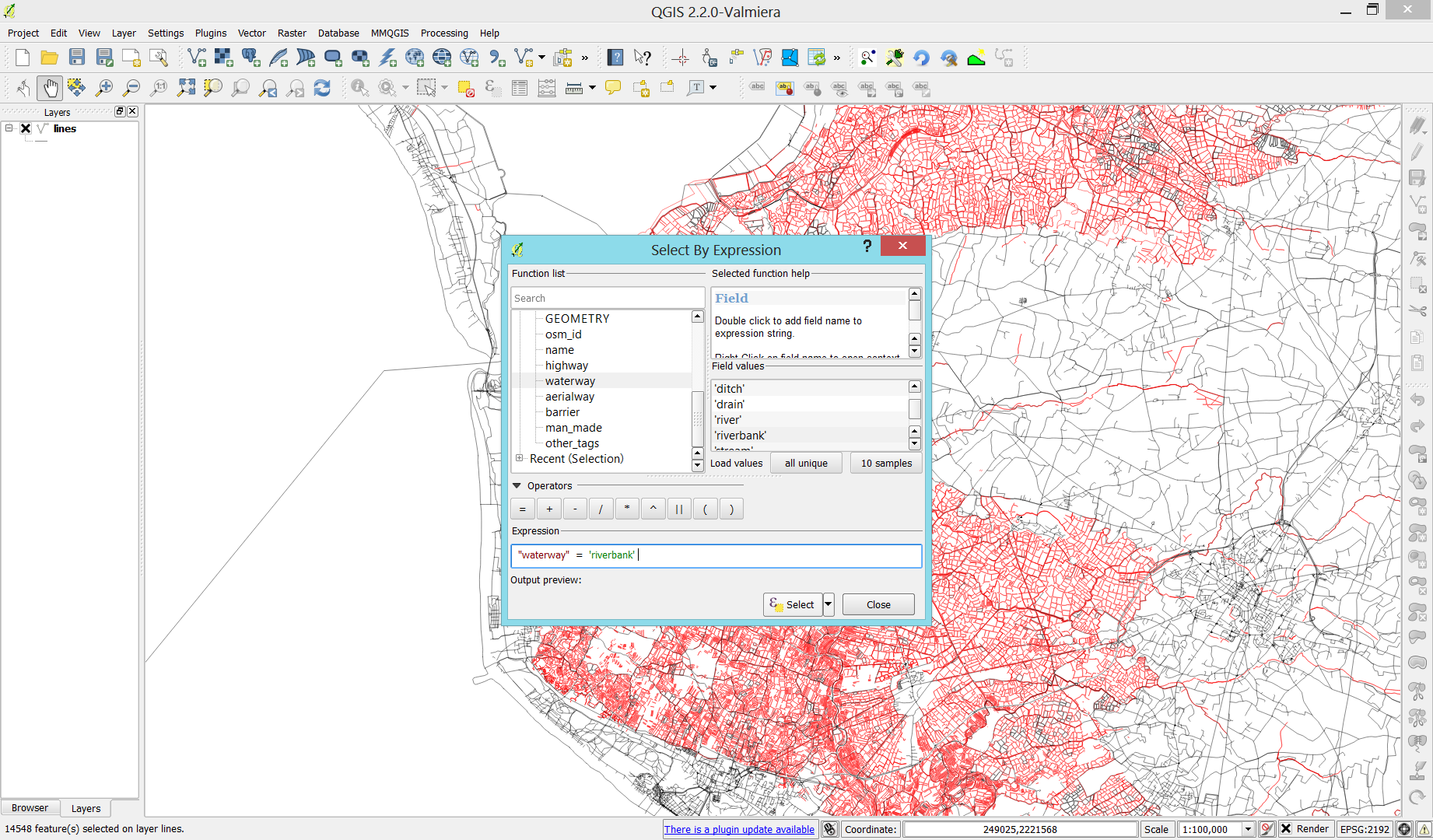
- First, we need to select all the lines where
waterway=riverbank.

- Then, we can use the Polygonize tool from the processing toolbox to automatically create polygons from the areas enclosed by the selected riverbank lines. (Note that Processing by default operates only on the selected features but this setting can be changed in the Processing settings.)

Creating the land polygon (or sea polygon if you prefer that for some reason) is a little more involved since most of the time the coastline will not be closed for the simple reason that we are often cutting a piece of land out of the main continent. Therefore, before we can use the Polygonize tools, we have to close the area. To do that, I suggest to first select the coastline using "other_tags" LIKE '%"natural"=>"coastline"%' and create a new layer from this selection (save selection as …) and edit it (don’t forget to enable snapping!) to add lines to close the area. Then polygonize.

Styling the data
Now that all preprocessing is done, we can focus on the styling.
You can get the styles used in the map from my Github QGIS-resources repository:
- osm_spatialite_googlemaps_multipolygon.qml … rule-based renderer incl. rules for: water, natural, residential areas and airports
- osm_spatialite_googlemaps_lines.qml … rule-based renderer incl. rules for roads, rails, and rivers, as well as rules for labels
- osm_spatialite_googlemaps_roadshields.qml … special label style for road shields
- osm_spatialite_googlemaps_places.qml … label style for populated places such as cities and towns