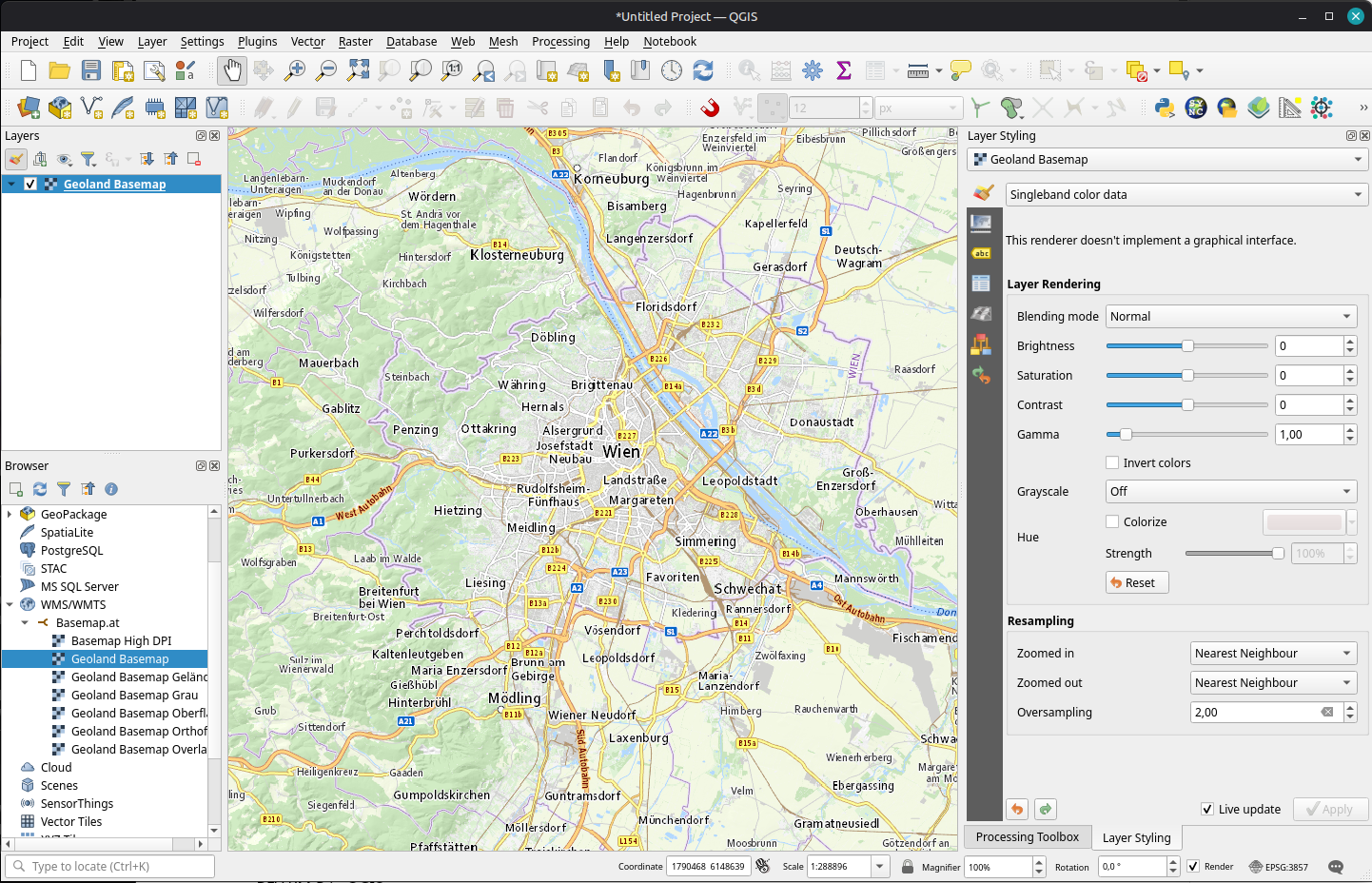
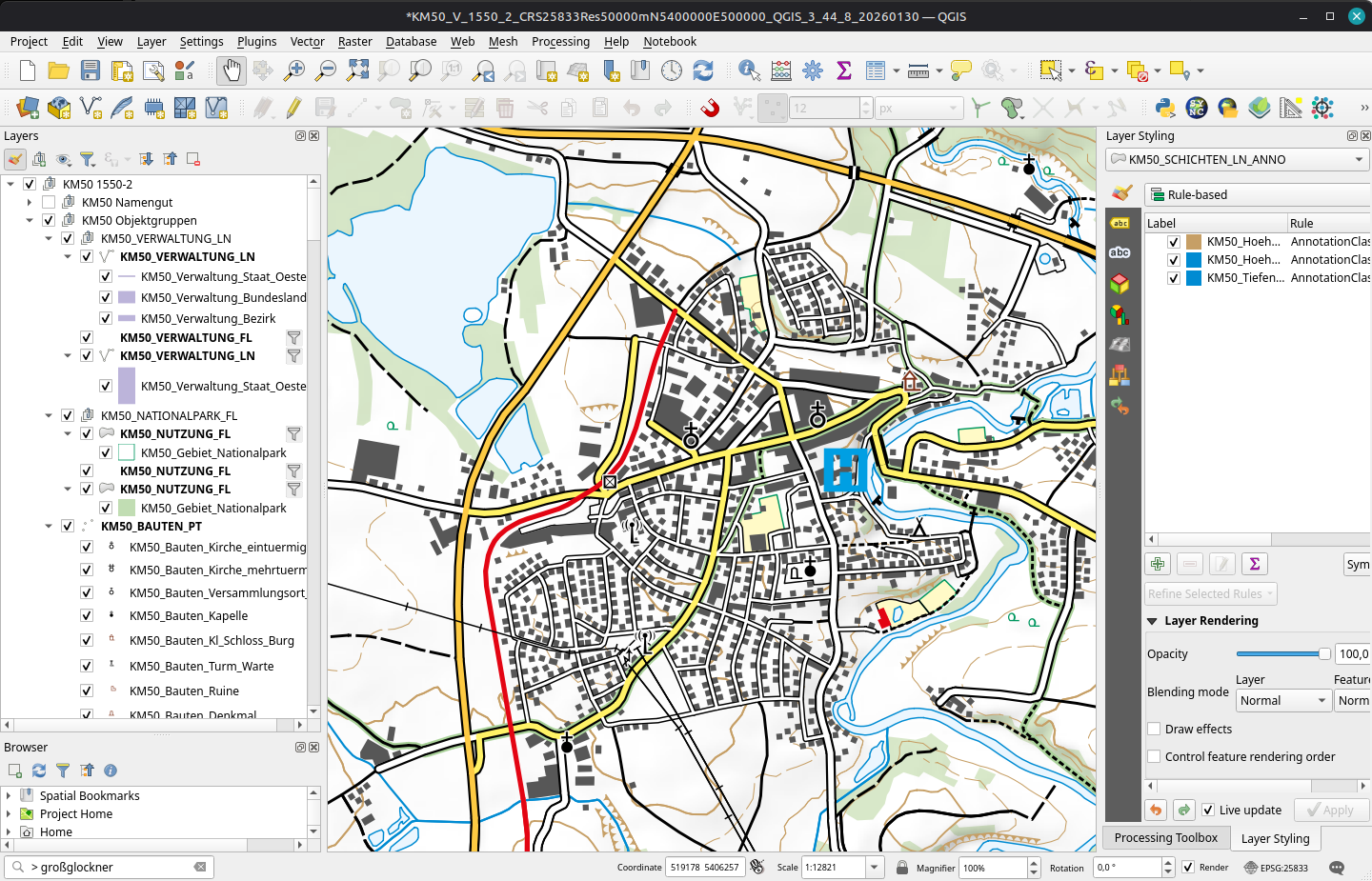
For many years now, we have been enjoying the basemap.at service with it’s various basemap options (color, gray, with/without labels, …) in WMTS and vector tiles.
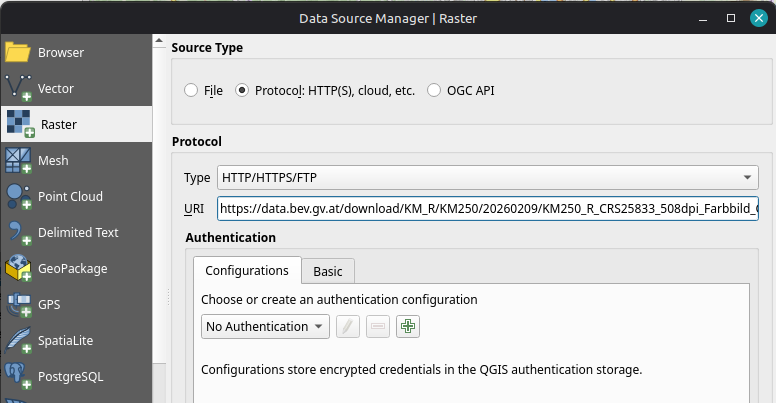
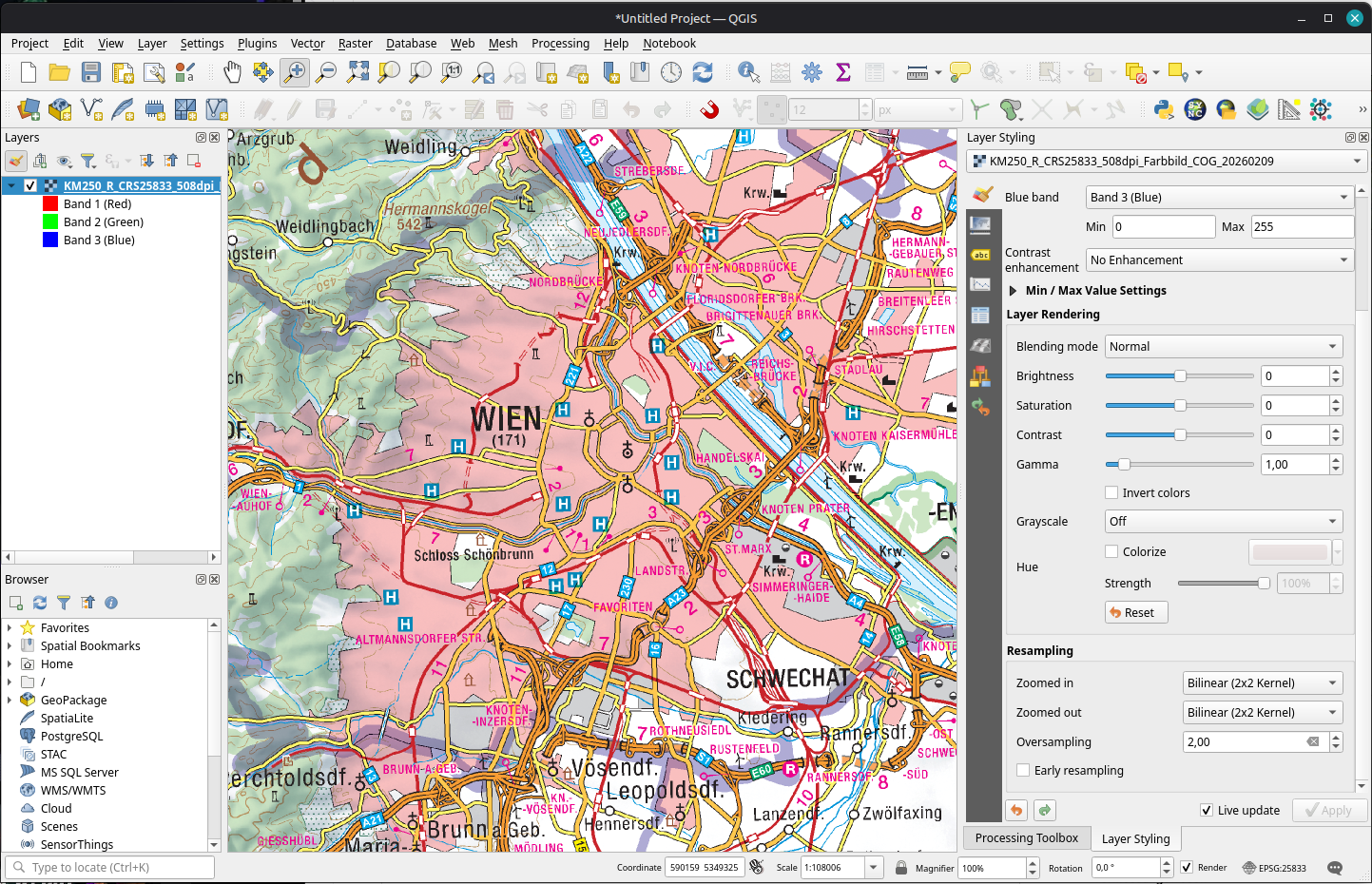
For a few weeks now, there is an additional service by BEV: Their cartographic models “Kartographischen Modelle (KM)” are now available as raster (KM-R) in COG-TIFF format.
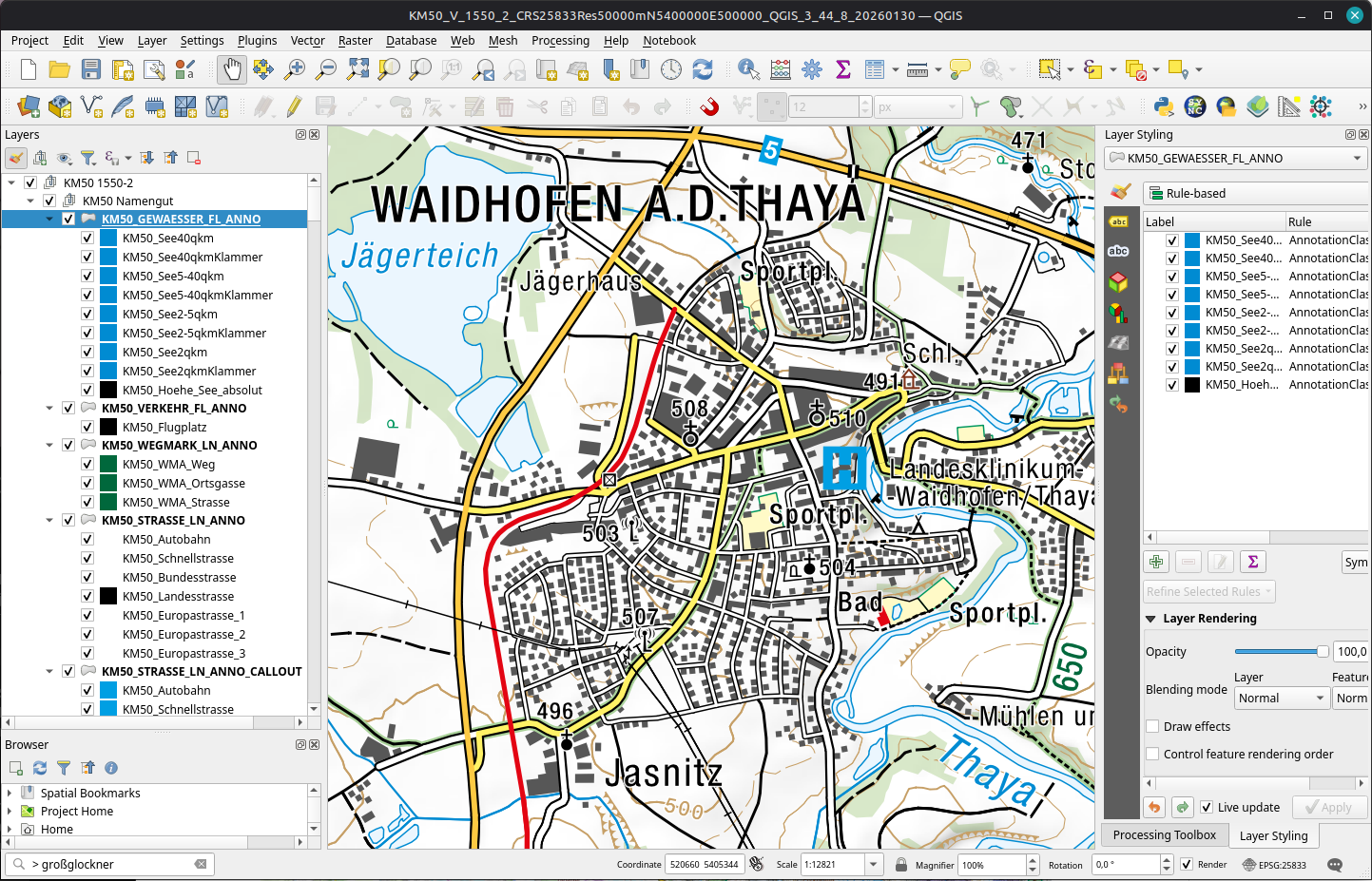
Some vector (KM-V) in GeoPackages with QGIS projects providing the layer style and label settings are already available for the Stichtag 30.01.2026 downloads. And they look awesome:
BEV KM-V project defaultsAnd without labels
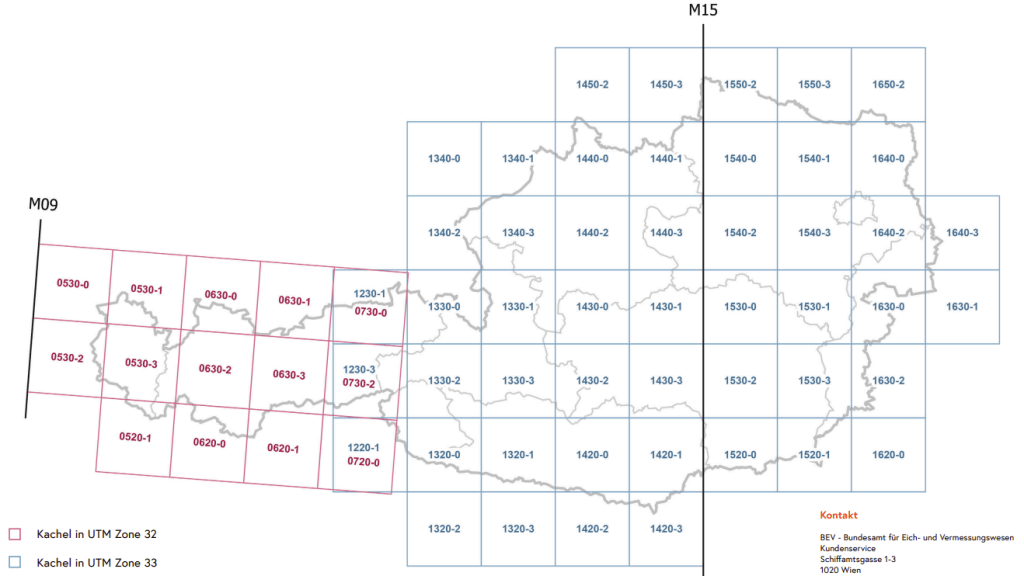
KM-V downloads are provided in tiles, so it’s not quite as simple as grabbing the COG URI:
It’s worth noting though, that the KM-V GeoPackages are still a work in progress and not all tiles are available for download yet.
I’ll keep an eye on the downloads to see when the rest of the tiles become available.
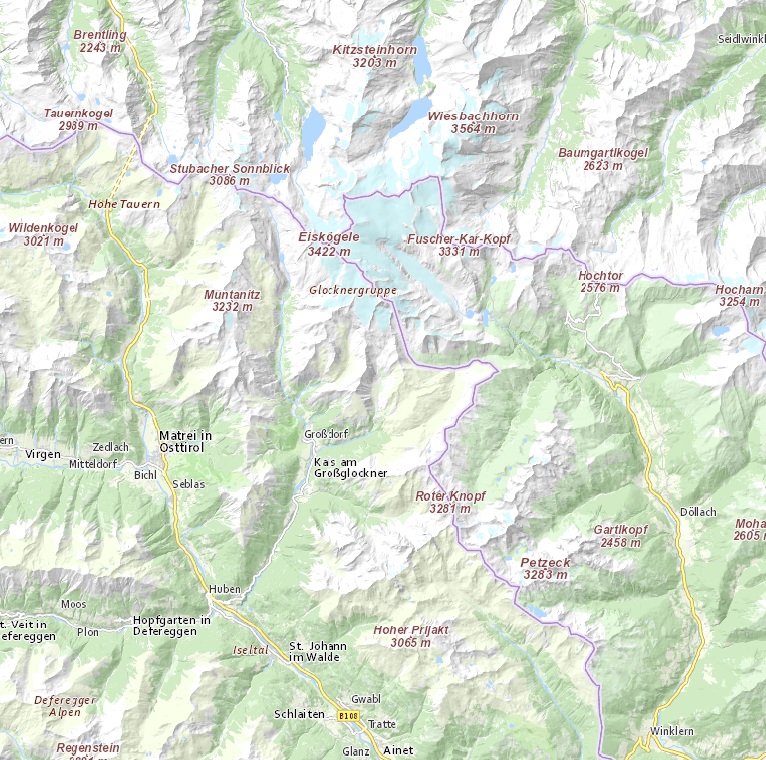
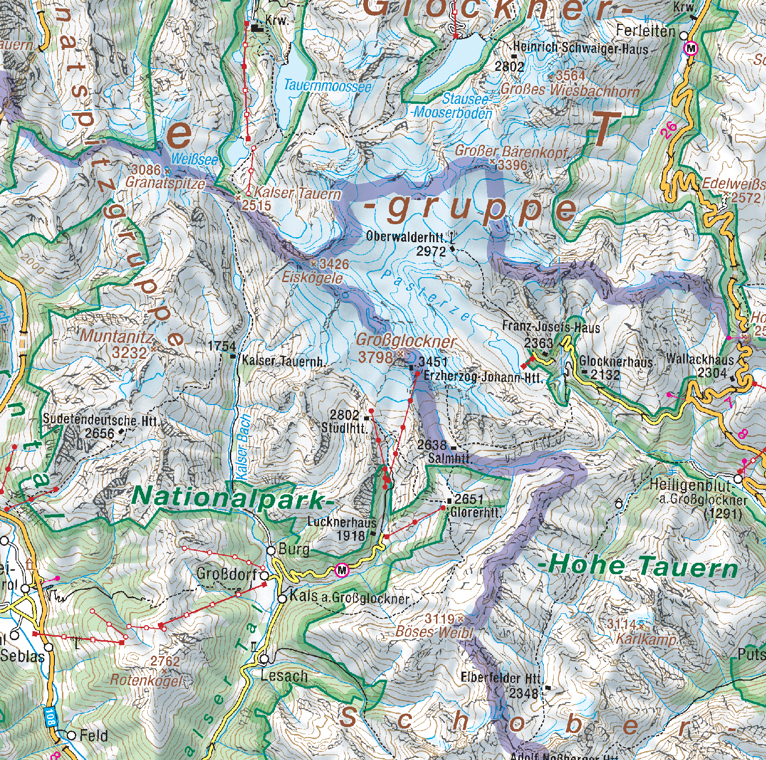
Until then, I leave you with a couple of examples of the Großglockner (highest mountain in Austria) area in basemap.at and KM-R side-by-side:
The last time I preprocessed the whole GeoLife dataset, I loaded it into PostGIS. Today, I want to share a new workflow that creates a (Geo)Parquet file and that is much faster.
The dataset (GeoLife)
“This GPS trajectory dataset was collected in (Microsoft Research Asia) Geolife project by 182 users in a period of over three years (from April 2007 to August 2012). A GPS trajectory of this dataset is represented by a sequence of time-stamped points, each of which contains the information of latitude, longitude and altitude. This dataset contains 17,621 trajectories with a total distance of about 1.2 million kilometers and a total duration of 48,000+ hours. These trajectories were recorded by different GPS loggers and GPS-phones, and have a variety of sampling rates. 91 percent of the trajectories are logged in a dense representation, e.g. every 1~5 seconds or every 5~10 meters per point.”
But today, we want to do to get a bit more involved …
DuckDB SQL magic
The issues we need to solve are:
Read all CSV files from all subdirectories
Parse the CSV, ignoring the first couple of lines, while assigning proper column names
Assign the CSV file name as the trajectory ID (because there is no ID in the original files)
Create point geometries that will work with our GeoParquet file
Create proper datetimes from the separate date and time fields
Luckily, DuckDB’s read_csv function comes with the necessary features built-in. Putting it all together:
CREATE OR REPLACE TABLE geolife AS
SELECT
parse_filename(filename, true) as vehicle_id,
strptime(date||' '||time, '%c') as t,
ST_Point(lon, lat) as geometry -- do NOT use ST_MakePoint
FROM read_csv('/home/anita/Documents/Geodata/Geolife/Geolife Trajectories 1.3/Data/*/*/*.plt',
skip=6,
filename = true,
columns = {
'lat': 'DOUBLE',
'lon': 'DOUBLE',
'ignore': 'INT',
'alt': 'DOUBLE',
'epoch': 'DOUBLE',
'date': 'VARCHAR',
'time': 'VARCHAR'
});
It’s blazingly fast:
I haven’t tested reading directly from ZIP archives yet, but there seems to be a community extension (zipfs) for this exact purpose.
Ready to QGIS
GeoParquet files can be drag-n-dropped into QGIS:
I’m running QGIS 3.42.1-Münster from conda-forge on Linux Mint.
Yes, it takes a while to render all 25 million points … But you know what? It get’s really snappy once we zoom in closer, e.g. to the situation in Germany:
Let’s have a closer look at what’s going on here.
Trajectools time
Selecting the 9,438 points in this extent, let’s compute movement metrics (speed & direction) and create trajectory lines:
Looks like we have some high-speed sections in there (with those red > 100 km/h streaks):
When we zoom in to Darmstadt and enable the trajectories layer, we can see each individual trip. Looks like car trips on the highway and walks through the city:
That looks like quite the long round trip:
Let’s see where they might have stopped to have a break:
If I had to guess, I’d say they stayed at the Best Western:
Conclusion
DuckDB has been great for this ETL workflow. I didn’t use much of its geospatial capabilities here but I was pleasantly surprised how smooth the GeoParquet creation process has been. Geometries are handled without any special magic and are recognized by QGIS. Same with the timestamps. All ready for more heavy spatiotemporal analysis with Trajectools.
If you haven’t tried DuckDB or GeoParquet yet, give it a try, particularly if you’re collaborating with data scientists from other domains and want to exchange data.
The QGISUC2025 team has done an awesome job recording and editing the conference presentations. All “presentation” type talks where the presenter has accepted to be published are now available in a dedicated list on the QGIS Youtube channel.
I also had the pleasure of presenting our Trajectools plugin and you can see this talk here:
Thank you to all the organizers, speakers, and participants for the great time!
written together with my fellow co-authors and EMERALDS project team member Argyrios Kyrgiazos.
For the technically inclined, the highlight are the presented UDFs in Snowflake to process and transform the trajectory data. For example, here’s a TemporalSplitter UDF:
CREATE OR REPLACE FUNCTION CARTO_DATABASE.CARTO.TemporalSplitter(geom ARRAY, t ARRAY, mode STRING)
RETURNS ARRAY
LANGUAGE PYTHON
RUNTIME_VERSION = 3.11
PACKAGES = ('numpy','pandas', 'geopandas','movingpandas', 'shapely')
HANDLER = 'udf'
AS $$
import numpy as np
import pandas as pd
import geopandas as gpd
import movingpandas as mpd
import shapely
from shapely.geometry import shape, mapping, Point, Polygon
from shapely.validation import make_valid
from datetime import datetime, timedelta
def udf(geom, t, mode):
valid_df = pd.DataFrame(geom, columns=['geometry'])
valid_df['t'] = pd.to_datetime(t)
valid_df['geometry'] = valid_df['geometry'].apply(lambda x:shapely.wkt.loads(x))
gdf = gpd.GeoDataFrame(valid_df, geometry='geometry', crs='epsg:4326')
gdf = gdf.set_index('t')
traj = mpd.Trajectory(gdf, 1)
traj_sm = mpd.TemporalSplitter(traj).split(mode=mode)
if len(traj_sm.trajectories)>0:
res = traj_sm.to_point_gdf()
res['geometry'] = res['geometry'].apply(lambda x: shapely.wkt.dumps(x))
return res.reset_index().values
else:
return []
$$;
Today marks the release of Trajectools 2.3 which brings a new set of algorithms, including trajectory generalizing, cleaning, and smoothing.
To give you a quick impression of what some of these algorithms would be useful for, this post introduces a trajectory preprocessing workflow that is quite general-purpose and can be adapted to many different datasets.
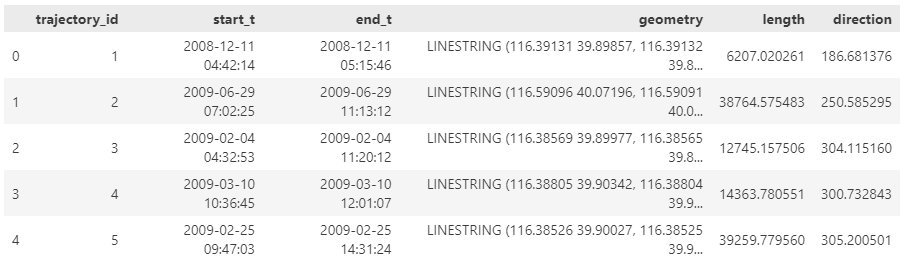
We start out with the Geolife sample dataset which you can find in the Trajectools plugin directory’s sample_data subdirectory. This small dataset includes 5908 points forming 5 trajectories, based on the trajectory_id field:
We first split our trajectories by observation gaps to ensure that there are no large gaps in our trajectories. Let’s make at cut at 15 minutes:
This splits the original 5 trajectories into 11 trajectories:
When we zoom, for example, to the two trajectories in the north western corner, we can see that the trajectories are pretty noisy and there’s even a spike / outlier at the western end:
If we label the points with the corresponding speeds, we can see how unrealistic they are: over 300 km/h!
Let’s remove outliers over 50 km/h:
Better but not perfect:
Let’s smooth the trajectories to get rid of more of the jittering.
(You’ll need to pip/mamba install the optional stonesoup library to get access to this algorithm.)
Depending on the noise values we chose, we get more or less smoothing:
Let’s zoom out to see the whole trajectory again:
Feel free to pan around and check how our preprocessing affected the other trajectories, for example:
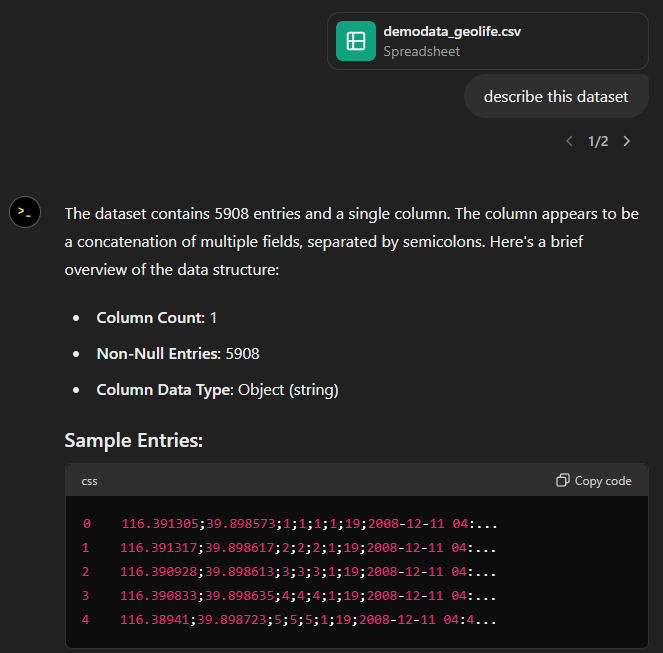
Today, I took ChatGPT’s Data Analyst for a spin. You’ve probably seen the fancy advertising videos: just drop in a dataset and AI does all the analysis for you?! Let’s see …
Of course, I’m not going to use some lame movie database or flower petals data. Instead, let’s go all in and test with a movement dataset.
You don’t get a second chance to make a first impression, they say. — Well, Data Analyst, you didn’t impress on the first try. How hard can it be to guess the delimiter and act accordingly?
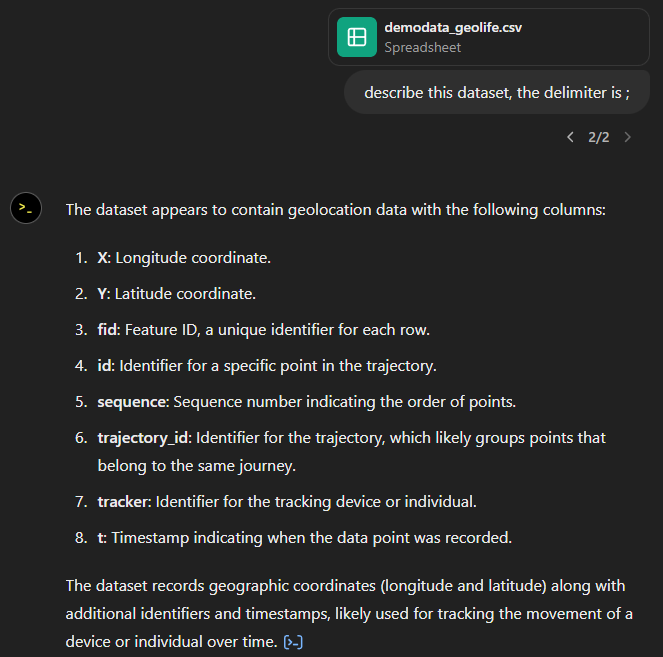
Anyway, let’s help it a little:
That looks much better. It makes an effort to guess what the columns could mean and successfully identifies the spatiotemporal information.
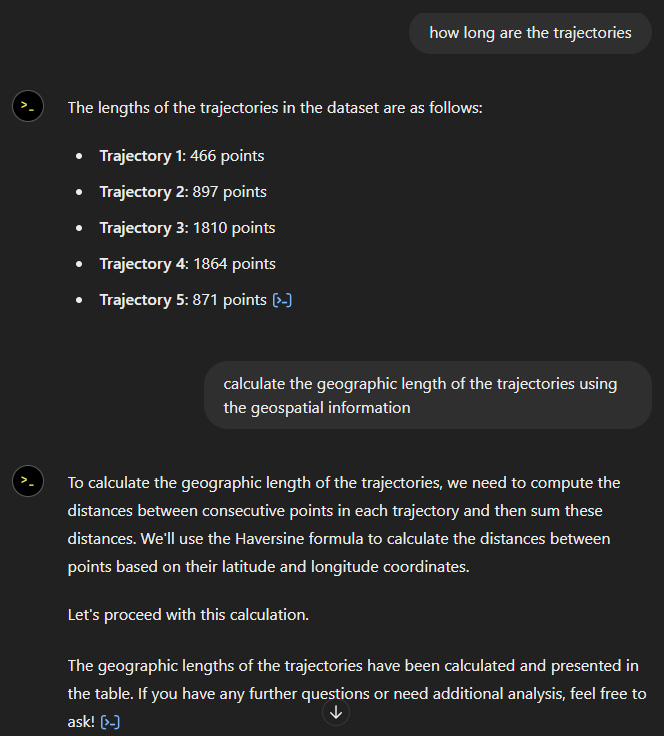
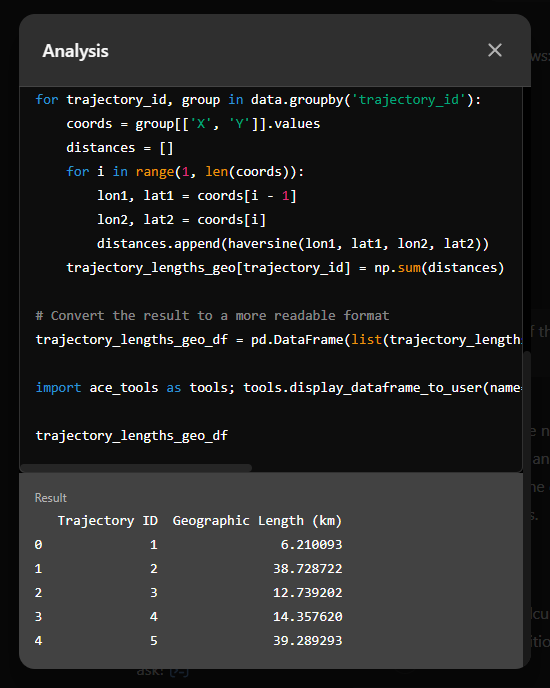
Now for some spatial analysis. On first try, it didn’t want to calculate the length of the trajectories in geographic terms, but we can make it to:
It will also show the code used to get to the results:
And indeed, these are close enough to the results computed using MovingPandas:
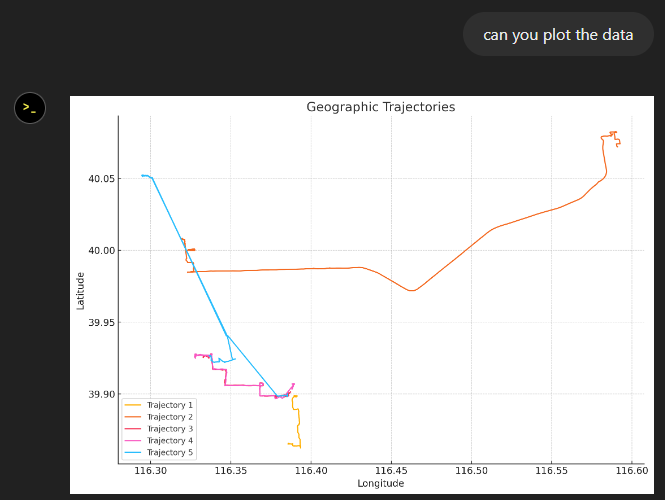
“What about plots?” I hear you ask.
For a first try, not bad at all:
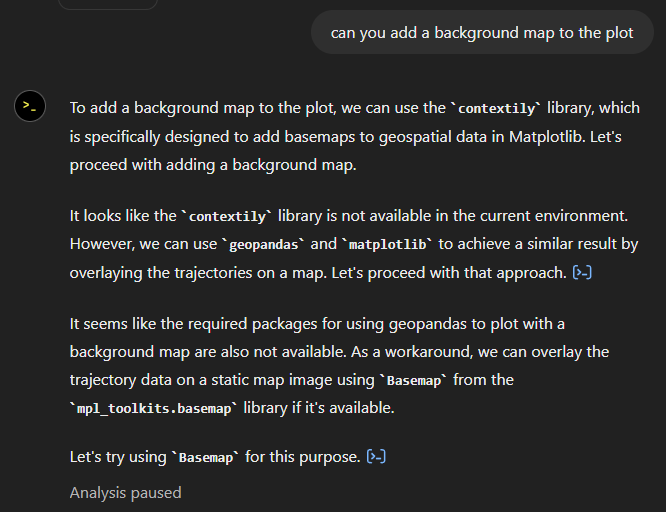
Let’s see if we can push it further:
Looks like poor Data Analyst ended up in geospatial library dependency hell 😈
It’s interesting to watch it try find a solution.
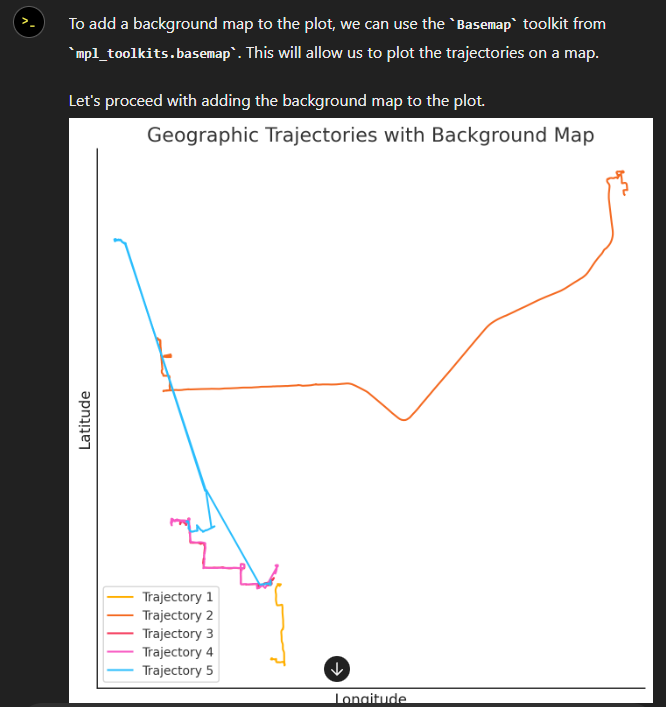
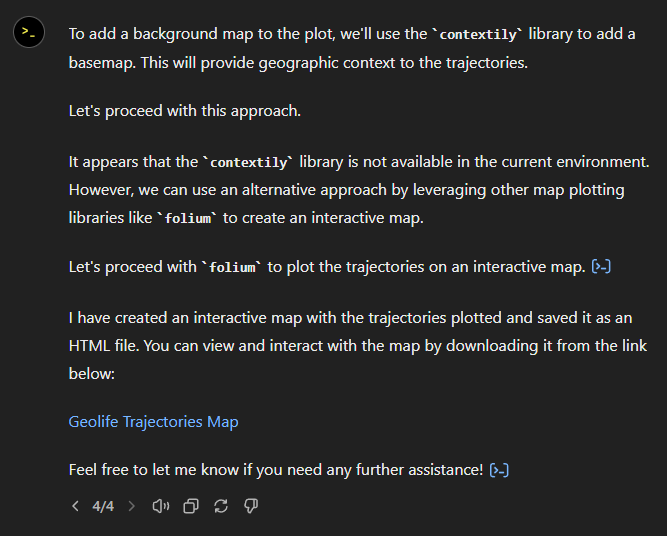
Alas, no background map appears:
Not giving up yet :)
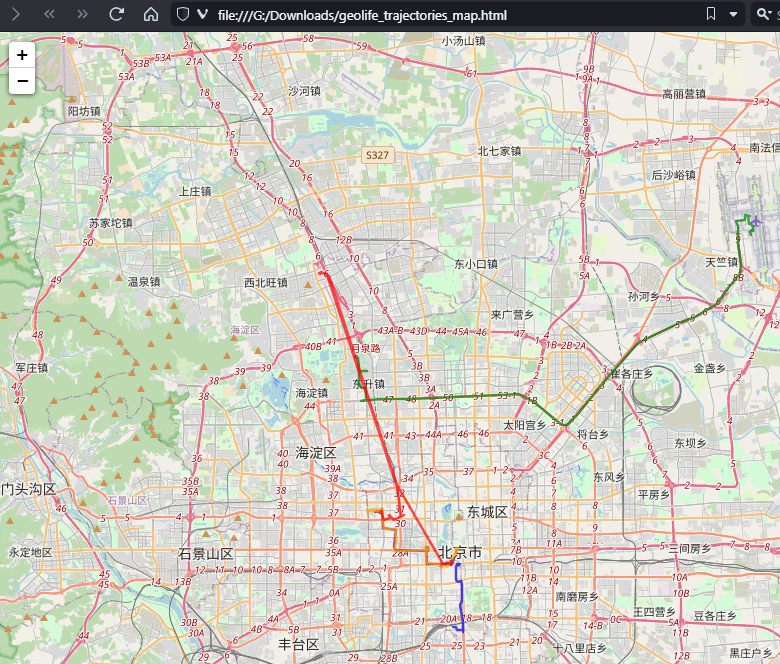
Woah, what happened here? It claims it created an interactive map in an HTML file.
And indeed it did:
This has been a very interesting experiment for me with many highs and lows. The whole process is a bit hit and miss. But when it does work, it’s fun.
I wasn’t sure what to expect with regards to Data Analyst’s spatial data processing capabilities. Looks like there are enough examples in its training data to find solutions for the basic trajectory analysis problems I asked it solve today, eventually, at least.
What’s the conclusion? Most AI marketing videos are severely overselling the capabilities of these tools. However, that doesn’t mean that they are completely useless, either. I’m looking forward to seeing the age of smaller open source models specifically trained for geospatial analysis to finally make it unnecessary for humans to memorize data analysis library syntax.
Today marks the 2.1 release of Trajectools for QGIS. This release adds multiple new algorithms and improvements. Since some improvements involve upstream MovingPandas functionality, I recommend to also update MovingPandas while you’re at it.
If you have installed QGIS and MovingPandas via conda / mamba, you can simply:
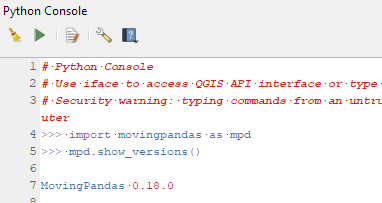
Afterwards, you can check that the library was correctly installed using:
import movingpandas as mpd mpd.show_versions()
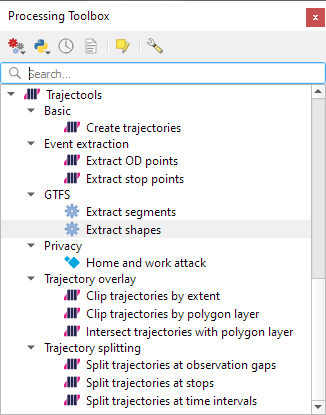
Trajectools 2.1
The new Trajectools algorithms are:
Trajectory overlay — Intersect trajectories with polygon layer
Privacy — Home work attack (requires scikit-mobility)
This algorithm determines how easy it is to identify an individual in a dataset. In a home and work attack the adversary knows the coordinates of the two locations most frequently visited by an individual.
Furthermore, we have fixed issue with previously ignored minimum trajectory length settings.
Scikit-mobility and gtfs_functions are optional dependencies. You do not need to install them, if you do not want to use the corresponding algorithms. In any case, they can be installed using mamba and pip:
There are a couple of existing plugins that deal with GTFS. However, in my experience, they either don’t integrate with Processing and/or don’t provide the functions I was expecting.
So far, we have two GTFS algorithms to cover essential public transport analysis needs:
The “Extract shapes” algorithm gives us the public transport routes:
The “Extract segments” algorithm has one more options. In addition to extracting the segments between public transport stops, it can also enrich the segments with the scheduled vehicle speeds:
Here you can see the scheduled speeds:
To show the stops, we can put marker line markers on the segment start and end locations:
The segments contain route information and stop names, so these can be extracted and used for labeling as well:
I’m continuously testing the algorithms integrated so far to see if they work as GIS users would expect and can to ensure that they can be integrated in Processing model seamlessly.
Because naming things is tricky, I’m currently struggling with how to best group the toolbox algorithms into meaningful categories. I looked into the categories mentioned in OGC Moving Features Access but honestly found them kind of lacking:
… but I’m not convinced yet. So take the above listed three categories with a grain of salt. Those may change before the release. (Any inputs / feedback / recommendation welcome!)
Let me close this quick status update with a screencast showcasing stop detection in AIS data, featuring the recently added trajectory styling using interpolated lines:
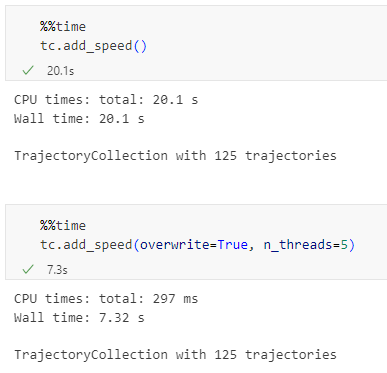
A prime example, are the relationships between GTFS StopTime and Trip nodes. For example, this is the Cypher query to get all StopTime nodes of Trip 17:
MATCH
(t:Trip {id: "17"})
<-[:BELONGS_TO]-
(st:StopTime)
RETURN st
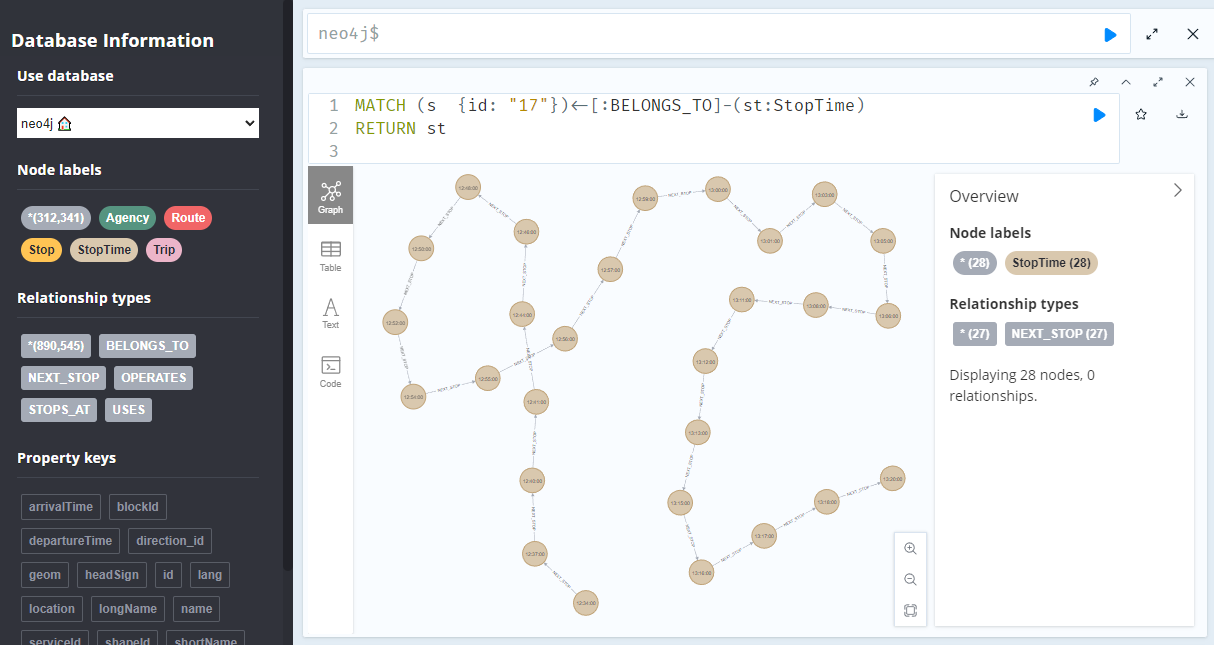
To get the stop locations, we also need to get the stop nodes:
MATCH
(t:Trip {id: "17"})
<-[:BELONGS_TO]-
(st:StopTime)
-[:STOPS_AT]->
(s:Stop)
RETURN st ,s
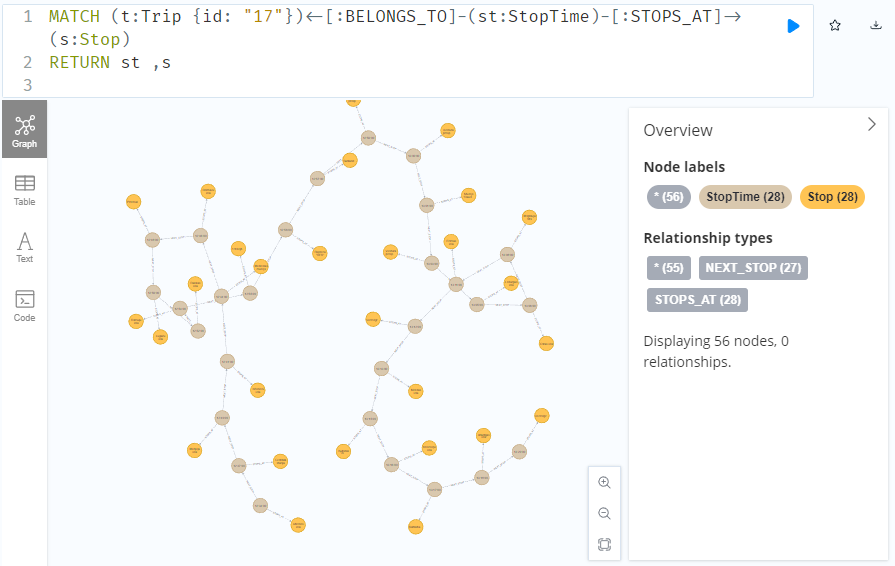
Adapting our code from the previous post, we can plot the stops:
from shapely.geometry import Point
QUERY = """MATCH (
t:Trip {id: "17"})
<-[:BELONGS_TO]-
(st:StopTime)
-[:STOPS_AT]->
(s:Stop)
RETURN st ,s
ORDER BY st.stopSequence
"""
with driver.session(database="neo4j") as session:
tx = session.begin_transaction()
results = tx.run(QUERY)
df = results.to_df(expand=True)
gdf = gpd.GeoDataFrame(
df[['s().prop.name']], crs=4326,
geometry=df["s().prop.location"].apply(Point)
)
tx.close()
m = gdf.explore()
m
Ordering by stop sequence is actually completely optional. Technically, we could use the sorted GeoDataFrame, and aggregate all the points into a linestring to plot the route. But I want to try something different: we’ll use the NEXT_STOP relationships to get a DataFrame of the start and end stops for each segment:
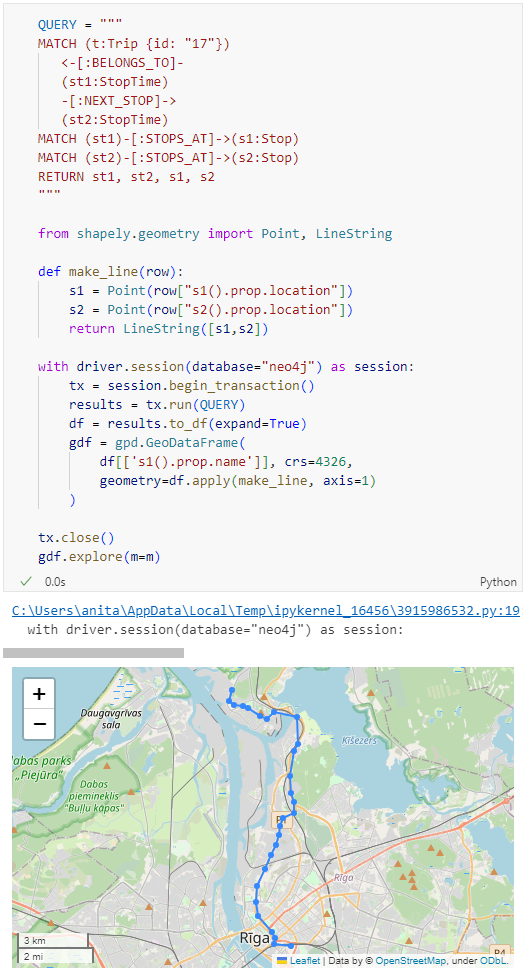
QUERY = """
MATCH (t:Trip {id: "17"})
<-[:BELONGS_TO]-
(st1:StopTime)
-[:NEXT_STOP]->
(st2:StopTime)
MATCH (st1)-[:STOPS_AT]->(s1:Stop)
MATCH (st2)-[:STOPS_AT]->(s2:Stop)
RETURN st1, st2, s1, s2
"""
from shapely.geometry import Point, LineString
def make_line(row):
s1 = Point(row["s1().prop.location"])
s2 = Point(row["s2().prop.location"])
return LineString([s1,s2])
with driver.session(database="neo4j") as session:
tx = session.begin_transaction()
results = tx.run(QUERY)
df = results.to_df(expand=True)
gdf = gpd.GeoDataFrame(
df[['s1().prop.name']], crs=4326,
geometry=df.apply(make_line, axis=1)
)
tx.close()
gdf.explore(m=m)
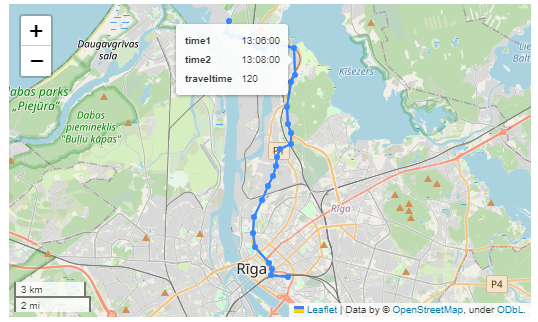
Finally, we can also use Cypher to calculate the travel time between two stops:
MATCH (t:Trip {id: "17"})
<-[:BELONGS_TO]-
(st1:StopTime)
-[:NEXT_STOP]->
(st2:StopTime)
MATCH (st1)-[:STOPS_AT]->(s1:Stop)
MATCH (st2)-[:STOPS_AT]->(s2:Stop)
RETURN st1.departureTime AS time1,
st2.arrivalTime AS time2,
s1.location AS geom1,
s2.location AS geom2,
duration.inSeconds(
time(st1.departureTime),
time(st2.arrivalTime)
).seconds AS traveltime