How to use Kaggle’s Taxi Trajectory Data in MovingPandas
Kaggle’s “Taxi Trajectory Data from ECML/PKDD 15: Taxi Trip Time Prediction (II) Competition” is one of the most used mobility / vehicle trajectory datasets in computer science. However, in contrast to other similar datasets, Kaggle’s taxi trajectories are provided in a format that is not readily usable in MovingPandas since the spatiotemporal information is provided as:
- TIMESTAMP: (integer) Unix Timestamp (in seconds). It identifies the trip’s start;
- POLYLINE: (String): It contains a list of GPS coordinates (i.e. WGS84 format) mapped as a string. The beginning and the end of the string are identified with brackets (i.e. [ and ], respectively). Each pair of coordinates is also identified by the same brackets as [LONGITUDE, LATITUDE]. This list contains one pair of coordinates for each 15 seconds of trip. The last list item corresponds to the trip’s destination while the first one represents its start;
Therefore, we need to create a DataFrame with one point + timestamp per row before we can use MovingPandas to create Trajectories and analyze them.
But first things first. Let’s download the dataset:
import datetime
import pandas as pd
import geopandas as gpd
import movingpandas as mpd
import opendatasets as od
from os.path import exists
from shapely.geometry import Point
input_file_path = 'taxi-trajectory/train.csv'
def get_porto_taxi_from_kaggle():
if not exists(input_file_path):
od.download("https://www.kaggle.com/datasets/crailtap/taxi-trajectory")
get_porto_taxi_from_kaggle()
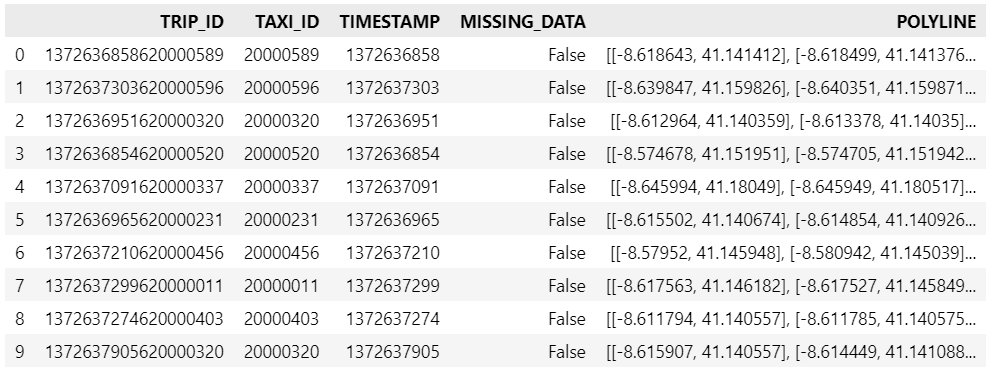
df = pd.read_csv(input_file_path, nrows=10, usecols=['TRIP_ID', 'TAXI_ID', 'TIMESTAMP', 'MISSING_DATA', 'POLYLINE'])
df.POLYLINE = df.POLYLINE.apply(eval) # string to list
df
And now for the remodelling:
def unixtime_to_datetime(unix_time):
return datetime.datetime.fromtimestamp(unix_time)
def compute_datetime(row):
unix_time = row['TIMESTAMP']
offset = row['running_number'] * datetime.timedelta(seconds=15)
return unixtime_to_datetime(unix_time) + offset
def create_point(xy):
try:
return Point(xy)
except TypeError: # when there are nan values in the input data
return None
new_df = df.explode('POLYLINE')
new_df['geometry'] = new_df['POLYLINE'].apply(create_point)
new_df['running_number'] = new_df.groupby('TRIP_ID').cumcount()
new_df['datetime'] = new_df.apply(compute_datetime, axis=1)
new_df.drop(columns=['POLYLINE', 'TIMESTAMP', 'running_number'], inplace=True)
new_df

And that’s it. Now we can create the trajectories:
trajs = mpd.TrajectoryCollection(
gpd.GeoDataFrame(new_df, crs=4326),
traj_id_col='TRIP_ID', obj_id_col='TAXI_ID', t='datetime')
trajs.hvplot(title='Kaggle Taxi Trajectory Data', tiles='CartoLight')

That’s it. Now our MovingPandas.TrajectoryCollection is ready for further analysis.
By the way, the plot above illustrates a new feature in the recent MovingPandas 0.16 release which, among other features, introduced plots with arrow markers that show the movement direction. Other new features include a completely new custom distance, speed, and acceleration unit support. This means that, for example, instead of always getting speed in meters per second, you can now specify your desired output units, including km/h, mph, or nm/h (knots).
This post is part of a series. Read more about movement data in GIS.
