In this post, Jakub Nowosad introduces our book “Geocomputation with Python”, also known as geocompy. It is an open-source book on geographic data analysis with Python, written by Michael Dorman, Jakub Nowosad, Robin Lovelace, and me with contributions from others. You can find it online at https://py.geocompx.org/
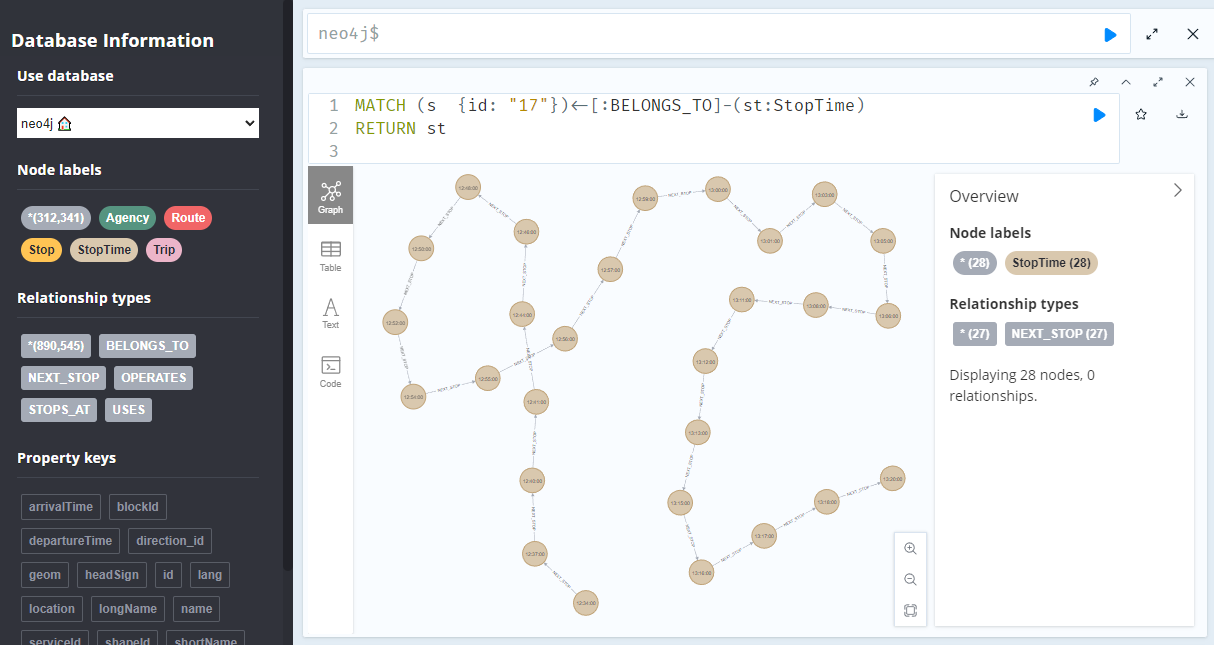
A prime example, are the relationships between GTFS StopTime and Trip nodes. For example, this is the Cypher query to get all StopTime nodes of Trip 17:
MATCH
(t:Trip {id: "17"})
<-[:BELONGS_TO]-
(st:StopTime)
RETURN st
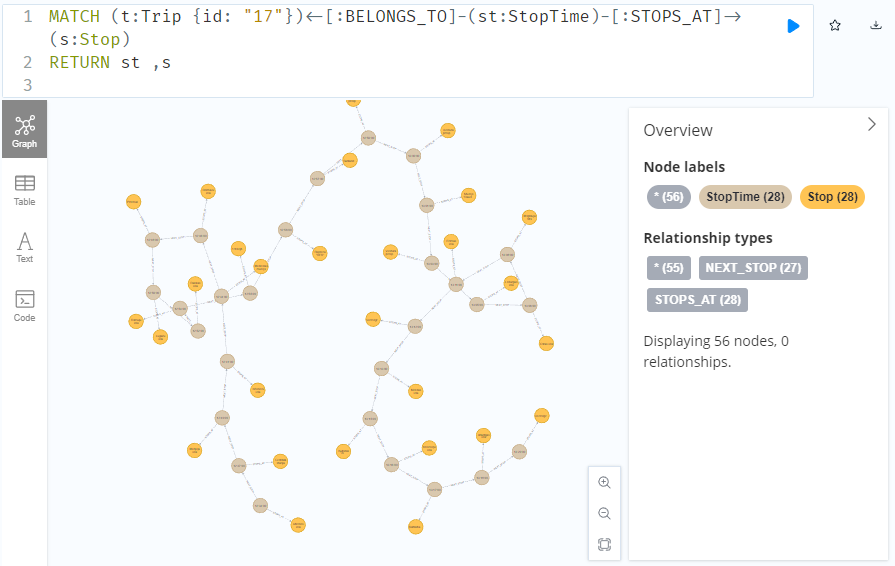
To get the stop locations, we also need to get the stop nodes:
MATCH
(t:Trip {id: "17"})
<-[:BELONGS_TO]-
(st:StopTime)
-[:STOPS_AT]->
(s:Stop)
RETURN st ,s
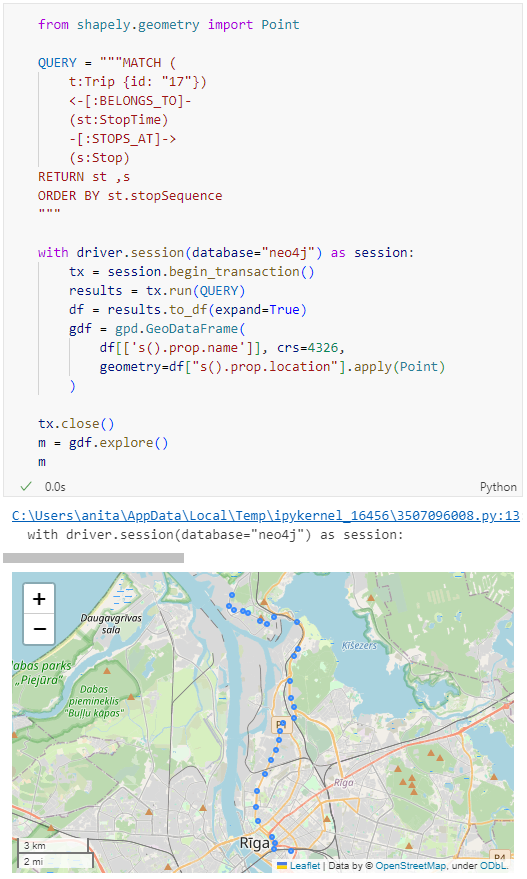
Adapting our code from the previous post, we can plot the stops:
from shapely.geometry import Point
QUERY = """MATCH (
t:Trip {id: "17"})
<-[:BELONGS_TO]-
(st:StopTime)
-[:STOPS_AT]->
(s:Stop)
RETURN st ,s
ORDER BY st.stopSequence
"""
with driver.session(database="neo4j") as session:
tx = session.begin_transaction()
results = tx.run(QUERY)
df = results.to_df(expand=True)
gdf = gpd.GeoDataFrame(
df[['s().prop.name']], crs=4326,
geometry=df["s().prop.location"].apply(Point)
)
tx.close()
m = gdf.explore()
m
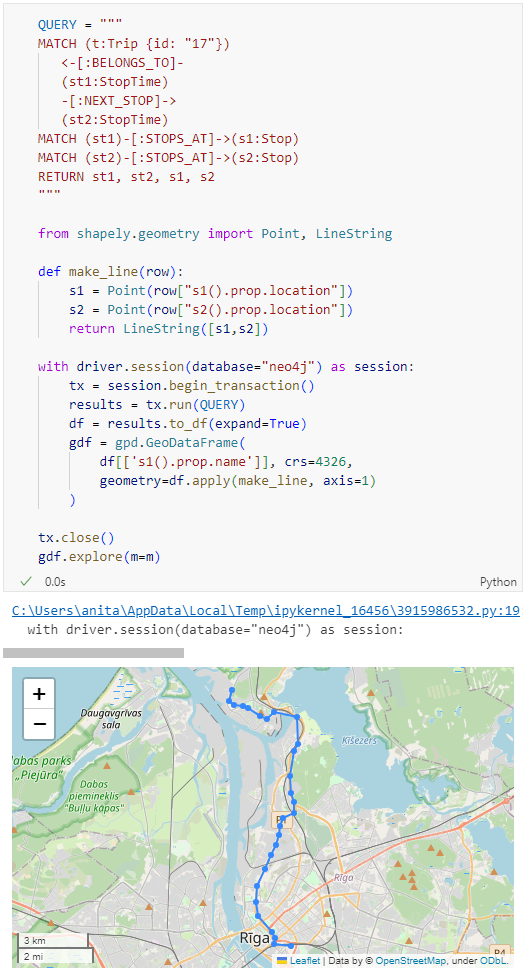
Ordering by stop sequence is actually completely optional. Technically, we could use the sorted GeoDataFrame, and aggregate all the points into a linestring to plot the route. But I want to try something different: we’ll use the NEXT_STOP relationships to get a DataFrame of the start and end stops for each segment:
QUERY = """
MATCH (t:Trip {id: "17"})
<-[:BELONGS_TO]-
(st1:StopTime)
-[:NEXT_STOP]->
(st2:StopTime)
MATCH (st1)-[:STOPS_AT]->(s1:Stop)
MATCH (st2)-[:STOPS_AT]->(s2:Stop)
RETURN st1, st2, s1, s2
"""
from shapely.geometry import Point, LineString
def make_line(row):
s1 = Point(row["s1().prop.location"])
s2 = Point(row["s2().prop.location"])
return LineString([s1,s2])
with driver.session(database="neo4j") as session:
tx = session.begin_transaction()
results = tx.run(QUERY)
df = results.to_df(expand=True)
gdf = gpd.GeoDataFrame(
df[['s1().prop.name']], crs=4326,
geometry=df.apply(make_line, axis=1)
)
tx.close()
gdf.explore(m=m)
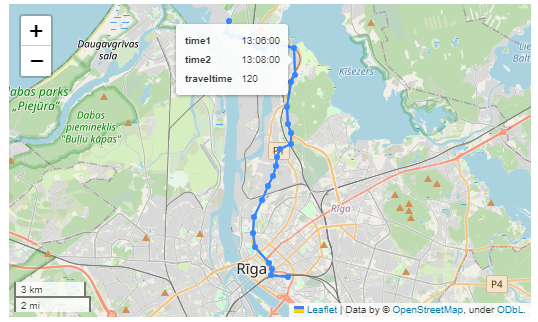
Finally, we can also use Cypher to calculate the travel time between two stops:
MATCH (t:Trip {id: "17"})
<-[:BELONGS_TO]-
(st1:StopTime)
-[:NEXT_STOP]->
(st2:StopTime)
MATCH (st1)-[:STOPS_AT]->(s1:Stop)
MATCH (st2)-[:STOPS_AT]->(s2:Stop)
RETURN st1.departureTime AS time1,
st2.arrivalTime AS time2,
s1.location AS geom1,
s2.location AS geom2,
duration.inSeconds(
time(st1.departureTime),
time(st2.arrivalTime)
).seconds AS traveltime
Today, we’ll take the next step and add basemaps to our maps. This is trickier than I would have expected. In particular, I was fighting with “invalid” OSM tile layers until I realized that my QGIS application instance somehow lacked the “WMS” provider.
In addition, getting basemaps to work also means that we have to take care of layer and project CRSes and on-the-fly reprojections. So let’s get to work:
from IPython.display import Image
from PyQt5.QtGui import QColor
from PyQt5.QtWidgets import QApplication
from qgis.core import QgsApplication, QgsVectorLayer, QgsProject, QgsRasterLayer, \
QgsCoordinateReferenceSystem, QgsProviderRegistry, QgsSimpleMarkerSymbolLayerBase
from qgis.gui import QgsMapCanvas
app = QApplication([])
qgs = QgsApplication([], False)
qgs.setPrefixPath(r"C:\temp", True) # setting a prefix path should enable the WMS provider
qgs.initQgis()
canvas = QgsMapCanvas()
project = QgsProject.instance()
map_crs = QgsCoordinateReferenceSystem('EPSG:3857')
canvas.setDestinationCrs(map_crs)
print("providers: ", QgsProviderRegistry.instance().providerList())
To add an OSM basemap, we use the xyz tiles option of the WMS provider:
This summer, I had the honor to — once again — speak at the OpenGeoHub Summer School. This time, I wanted to challenge the students and myself by not just doing MovingPandas but by introducing both MovingPandas and DVC for Mobility Data Science.
I’ve previously written about DVC and how it may be used to track geoprocessing workflows with QGIS & DVC. In my summer school session, we go into details on how to use DVC to keep track of MovingPandas movement data analytics workflow.
written together with my fellow “Geocomputation with Python” co-authors Robin Lovelace, Michael Dorman, and Jakub Nowosad.
In this blog post, we talk about our experience teaching R and Python for geocomputation. The context of this blog post is the OpenGeoHub Summer School 2023 which has courses on R, Python and Julia. The focus of the blog post is on geographic vector data, meaning points, lines, polygons (and their ‘multi’ variants) and the attributes associated with them. We plan to cover raster data in a future post.
Kaggle’s “Taxi Trajectory Data from ECML/PKDD 15: Taxi Trip Time Prediction (II) Competition” is one of the most used mobility / vehicle trajectory datasets in computer science. However, in contrast to other similar datasets, Kaggle’s taxi trajectories are provided in a format that is not readily usable in MovingPandas since the spatiotemporal information is provided as:
TIMESTAMP: (integer) Unix Timestamp (in seconds). It identifies the trip’s start;
POLYLINE: (String): It contains a list of GPS coordinates (i.e. WGS84 format) mapped as a string. The beginning and the end of the string are identified with brackets (i.e. [ and ], respectively). Each pair of coordinates is also identified by the same brackets as [LONGITUDE, LATITUDE]. This list contains one pair of coordinates for each 15 seconds of trip. The last list item corresponds to the trip’s destination while the first one represents its start;
Therefore, we need to create a DataFrame with one point + timestamp per row before we can use MovingPandas to create Trajectories and analyze them.
But first things first. Let’s download the dataset:
import datetime
import pandas as pd
import geopandas as gpd
import movingpandas as mpd
import opendatasets as od
from os.path import exists
from shapely.geometry import Point
input_file_path = 'taxi-trajectory/train.csv'
def get_porto_taxi_from_kaggle():
if not exists(input_file_path):
od.download("https://www.kaggle.com/datasets/crailtap/taxi-trajectory")
get_porto_taxi_from_kaggle()
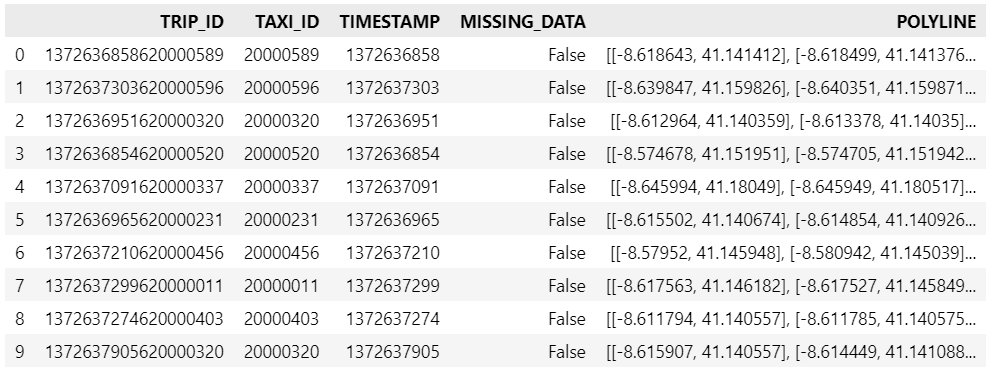
df = pd.read_csv(input_file_path, nrows=10, usecols=['TRIP_ID', 'TAXI_ID', 'TIMESTAMP', 'MISSING_DATA', 'POLYLINE'])
df.POLYLINE = df.POLYLINE.apply(eval) # string to list
df
And now for the remodelling:
def unixtime_to_datetime(unix_time):
return datetime.datetime.fromtimestamp(unix_time)
def compute_datetime(row):
unix_time = row['TIMESTAMP']
offset = row['running_number'] * datetime.timedelta(seconds=15)
return unixtime_to_datetime(unix_time) + offset
def create_point(xy):
try:
return Point(xy)
except TypeError: # when there are nan values in the input data
return None
new_df = df.explode('POLYLINE')
new_df['geometry'] = new_df['POLYLINE'].apply(create_point)
new_df['running_number'] = new_df.groupby('TRIP_ID').cumcount()
new_df['datetime'] = new_df.apply(compute_datetime, axis=1)
new_df.drop(columns=['POLYLINE', 'TIMESTAMP', 'running_number'], inplace=True)
new_df
And that’s it. Now we can create the trajectories:
That’s it. Now our MovingPandas.TrajectoryCollection is ready for further analysis.
By the way, the plot above illustrates a new feature in the recent MovingPandas 0.16 release which, among other features, introduced plots with arrow markers that show the movement direction. Other new features include a completely new custom distance, speed, and acceleration unit support. This means that, for example, instead of always getting speed in meters per second, you can now specify your desired output units, including km/h, mph, or nm/h (knots).
Similarly, we’ve seen posts on using PyQGIS in Jupyter notebooks. However, I find the setup with *.bat files rather tricky.
This post presents a way to set up a conda environment with QGIS that is ready to be used in Jupyter notebooks.
The first steps are to create a new environment and install QGIS. I use mamba for the installation step because it is faster than conda but you can use conda as well:
If we now try to import the qgis module in Python, we get an error:
(qgis) PS C:\Users\anita> python
Python 3.9.15 | packaged by conda-forge | (main, Nov 22 2022, 08:41:22) [MSC v.1929 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import qgis
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ModuleNotFoundError: No module named 'qgis'
To fix this error, we need to get the paths from the Python console inside QGIS:
New functions to add a timedelta column and get the trajectory sampling interval #233
As always, all tutorials are available from the movingpandas-examples repository and on MyBinder:
The new distance measures are covered in tutorial #11:
Computing distances between trajectories, as illustrated in tutorial #11Computing distances between a trajectory and other geometry objects, as illustrated in tutorial #11
But don’t miss the great features covered by the other notebooks, such as outlier cleaning and smoothing:
Trajectory cleaning and smoothing, as illustrated in tutorial #10
If you have questions about using MovingPandas or just want to discuss new ideas, you’re welcome to join our discussion forum.
Speed and direction column names can now be customized
If you have questions about using MovingPandas or just want to discuss new ideas, you’re welcome to join our recently opened discussion forum.
As always, all tutorials are available from the movingpandas-examples repository and on MyBinder:
Besides others examples, the movingpandas-examples repo contains the following tech demo: an interactive app built with Panel that demonstrates different MovingPandas stop detection parameters
To start the app, open the stopdetection-app.ipynb notebook and press the green Panel button in the Jupyter Lab toolbar:
Here’s a quick preview of the resulting app in action:
To create this app, I defined a single function called my_plot which takes the address and desired buffer size as input parameters. Using Panel’s interact and servable methods, I’m then turning this function into the interactive app you’ve seen above:
To open the Panel preview, press the green Panel button in the Jupyter Lab toolbar:
I really enjoy building spatial data exploration apps this way, because I can start off with a Jupyter notebook and – once I’m happy with the functionality – turn it into a pretty app that provides a user-friendly exterior and hides the underlying complexity that might scare away stakeholders.
Give it a try and share your own adventures. I’d love to see what you come up with.