Visualizations of raw movement data records, that is, simple point maps or point density (“heat”) maps provide very limited data exploration capabilities. Therefore, we need clever aggregation approaches that can actually reveal movement patterns. Many existing aggregation approaches, however, do not scale to large datasets. We therefore developed the M³ Massive Movement Model [1] which supports distributed computing environments and can be incrementally updated with new data.
This is part 1 of “Exploring massive movement datasets”.
Using state-of-the-art big gespatial tools, such as GeoMesa, it is quite straightforward to ingest, index and query large amounts of timestamped location records. Thanks to GeoMesa’s GeoServer integration, it is also possible to publish GeoMesa tables as WMS and WFS which can be visualized in QGIS and explored (for more about GeoMesa, see Scalable spatial vector data processing ).So far so good! But with this basic setup, we only get point maps and point density maps which don’t tell us much about important movement characteristics like speed and direction (particularly if the reporting interval between consecutive location records is irregular). Therefore, we developed an aggregation method which models local record density, as well as movement speed and direction which we call M³.
For distributed computation, we need to split large datasets into chunks. To build models of local movement characteristics, it makes sense to create spatial or spatiotemporal chunks that can be processed independently. We therefore split the data along a regular grid but instead of computing one average value per grid cell, we create a flexible number of prototypes that describe the movement in the cell. Each prototype models a location, speed, and direction distribution (mean and sigma).
In our paper, we used M³ to explore ship movement data. We turned roughly 4 billion AIS records into prototypes:

M³ for ship movement data during January to December 2017 (3.9 billion records turned into 3.4 million prototypes; computing time: 41 minutes)
The above plot really only gives a first impression of the spatial distribution of ship movement records. The real value of M³ becomes clearer when we zoom in and start exploring regional patterns. Then we can discover vessel routes, speeds, and movement directions:

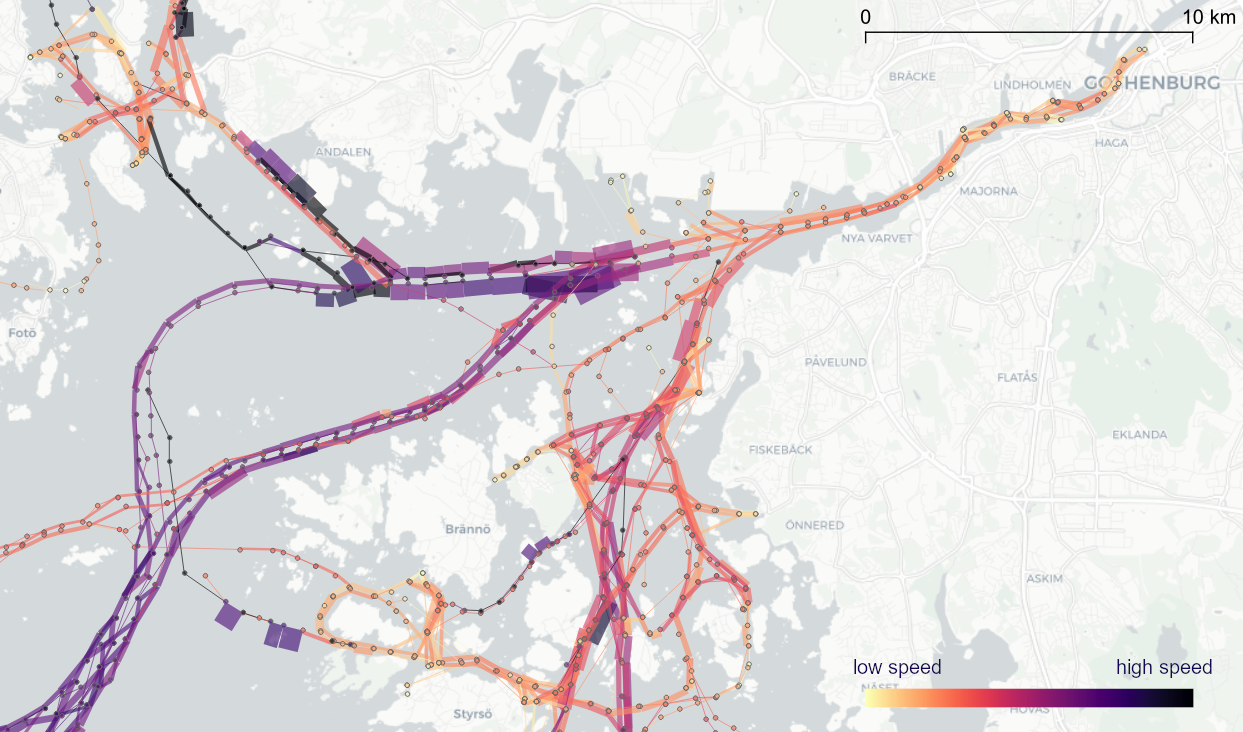
Cargo ship prototypes around Denmark

Cargo prototype details near Copenhagen & Malmö
The prototype details on the right side, in particular, show the strength of the prototype idea: even though the grid cells we use are rather large, the prototypes clearly form along vessel routes. We can see exactly where these routes are and what speeds ship travel there, without having to increase the grid resolution to impractical values. Slow prototypes with high direction sigma (red+black markers) are clear indicators of ports. The marker size shows the number of records per prototype and thus helps distinguish heavily traveled routes from minor ones.
M³ is implemented in Spark. We read raw location records from GeoMesa and write prototypes to GeoMesa. All maps have been created in QGIS using prototype data published as GeoServer WFS.
If you want to dive deeper, here’s the full paper:
[1] Graser. A., Widhalm, P., & Dragaschnig, M. (2020). The M³ massive movement model: a distributed incrementally updatable solution for big movement data exploration. International Journal of Geographical Information Science. doi:10.1080/13658816.2020.1776293.
This post is part of a series. Read more about movement data in GIS.