If you follow this blog, you’ll probably remember that I published a QGIS style for flow maps a while ago. The example showed domestic migration between the nine Austrian states, a rather small dataset. Even so, it required some manual tweaking to make the flow map readable. Even with only 72 edges, the map quickly gets messy:

Raw migration flows between Austrian states, line width scaled by flow strength
One popular approach in the data viz community to deal with this problem is edge bundling. The idea is to reduce visual clutter by generate bundles of similar edges.
Surprisingly, edge bundling is not available in desktop GIS. Existing implementations in the visual analytics field often run on GPUs because edge bundling is computationally expensive. Nonetheless, we have set out to implement force-directed edge bundling for the QGIS Processing toolbox [0]. The resulting scripts are available on Github.
The main procedure consists of two tools: bundle edges and summarize. Bundle edges takes the raw straight lines, and incrementally adds intermediate nodes (called control points) and shifts them according to computed spring and electrostatic forces. If the input are 72 lines, the output again are 72 lines but each line geometry has been bent so that similar lines overlap and form a bundle.

After this edge bundling step, most common implementations compute a line heatmap, that is, for each map pixel, determine the number of lines passing through the pixel. But QGIS does not support line heatmaps and this approach also has issues distinguishing lines that run in opposite directions. We have therefore implemented a summarize tool that computes the local strength of the generated bundles.

Continuing our previous example, if the input are 72 lines, summarize breaks each line into its individual segments and determines the number of segments from other lines that are part of the same bundle. If a weight field is specified, each line is not just counted once but according to its weight value. The resulting bundle strength can be used to create a line layer style with data-defined line width:

Bundled migration flows
To avoid overlaps of flows in opposing directions, we define a line offset. Finally, summarize also adds a sequence number to the line segments. This sequence number is used to assign a line color on the gradient that indicates flow direction.
I already mentioned that edge bundling is computationally expensive. One reason is that we need to perform pairwise comparison of edges to determine if they are similar and should be bundled. This comparison results in a compatibility matrix and depending on the defined compatibility threshold, different bundles can be generated.
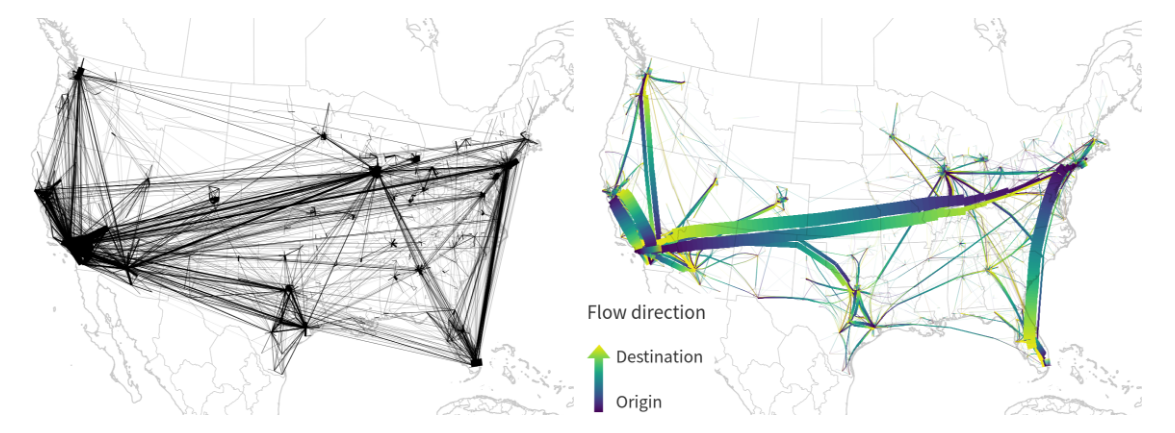
The following U.S. dataset contains around 4000 lines and bundling it takes a considerable amount of time.

One approach to speed up computations is to first use a quick clustering algorithm and then perform edge bundling on each cluster individually. If done correctly, clustering significantly reduces the size of each compatibility matrix.

In this example, we divided the edges into six clusters before bundling them. If you compare this result to the visualization at the top of this post (which did not use clustering), you’ll see some differences here and there but, overall, the results are quite similar:

Looking at these examples, you’ll probably spot a couple of issues. There are many additional ideas for potential improvements from existing literature which we have not implemented yet. If you are interested in improving these tools, please go ahead! The code and more examples are available on Github.
For more details, leave your email in a comment below and I’ll gladly send you the pre-print of our paper.
[0] Graser, A., Schmidt, J., Roth, F., & Brändle, N. (2017 online) Untangling Origin-Destination Flows in Geographic Information Systems. Information Visualization – Special Issue on Visual Movement Analytics.
This post is part of a series. Read more about movement data in GIS.