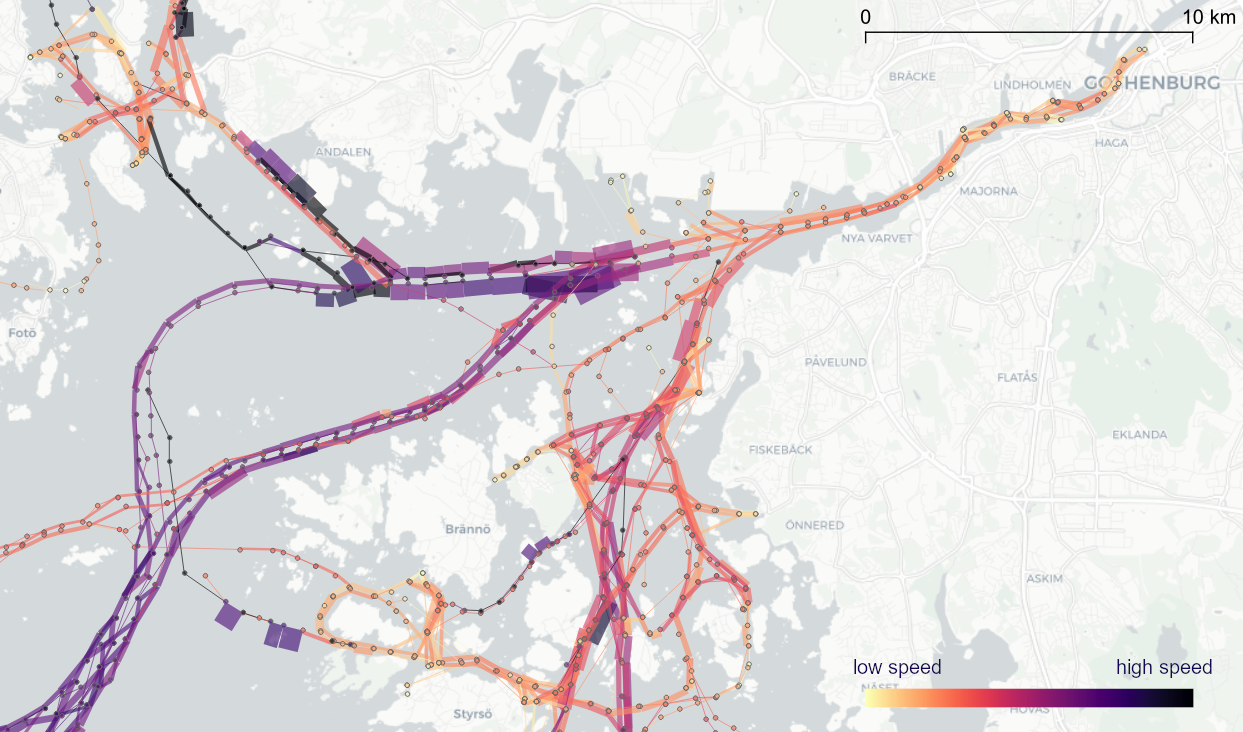
To explore travel patterns like origin-destination relationships, we need to identify individual trips with their start/end locations and trajectories between them. Extracting these trajectories from large datasets can be challenging, particularly if the records of individual moving objects don’t fit into memory anymore and if the spatial and temporal extent varies widely (as is the case with ship data, where individual vessel journeys can take weeks while crossing multiple oceans).
This is part 2 of “Exploring massive movement datasets”.
Roughly speaking, trip trajectories can be generated by first connecting consecutive records into continuous tracks and then splitting them at stops. This general approach applies to many different movement datasets. However, the processing details (e.g. stop detection parameters) and preprocessing steps (e.g. removing outliers) vary depending on input dataset characteristics.
For example, in our paper [1], we extracted vessel journeys from AIS data which meant that we also had to account for observation gaps when ships leave the observable (usually coastal) areas. In the accompanying 10-minute talk, I went through a 4-step trajectory exploration workflow for assessing our dataset’s potential for travel time prediction:

Click to watch the recorded talk
Like the M³ prototype computation presented in part 1, our trajectory aggregation approach is implemented in Spark. The challenges are both the massive amounts of trajectory data and the fact that operations only produce correct results if applied to a complete and chronologically sorted set of location records.This is challenging because Spark core libraries (version 2.4.5 at the time) are mostly geared towards dealing with unsorted data. This means that, when using high-level Spark core functionality incorrectly, an aggregator needs to collect and sort the entire track in the main memory of a single processing node. Consequently, when dealing with large datasets, out-of-memory errors are frequently encountered.
To solve this challenge, our implementation is based on the Secondary Sort pattern and on Spark’s aggregator concept. Secondary Sort takes care to first group records by a key (e.g. the moving object id), and only in the second step, when iterating over the records of a group, the records are sorted (e.g. chronologically). The resulting iterator can be used by an aggregator that implements the logic required to build trajectories based on gaps and stops detected in the dataset.
If you want to dive deeper, here’s the full paper:
[1] Graser, A., Dragaschnig, M., Widhalm, P., Koller, H., & Brändle, N. (2020). Exploratory Trajectory Analysis for Massive Historical AIS Datasets. In: 21st IEEE International Conference on Mobile Data Management (MDM) 2020. doi:10.1109/MDM48529.2020.00059
This post is part of a series. Read more about movement data in GIS.