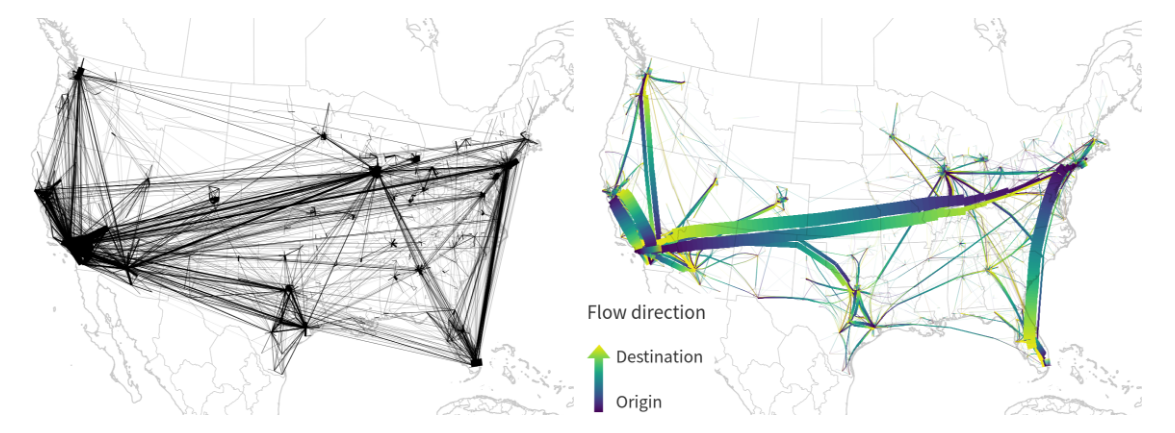
If you’ve been following my posts, you’ll no doubt have seen quite a few flow maps on this blog. This tutorial brings together many different elements to show you exactly how to create a flow map from scratch. It’s the result of a collaboration with Hans-Jörg Stark from Switzerland who collected the data.
The flow data
The data presented in this post stems from a survey conducted among public transport users, especially commuters (available online at: https://de.surveymonkey.com/r/57D33V6). Among other questions, the questionnair asks where the commuters start their journey and where they are heading.
The answers had to be cleaned up to correct for different spellings, spelling errors, and multiple locations in one field. This cleaning and the following geocoding step were implemented in Python. Afterwards, the flow information was aggregated to count the number of nominations of each connection between different places. Finally, these connections (edges that contain start id, destination id and number of nominations) were stored in a text file. In addition, the locations were stored in a second text file containing id, location name, and co-ordinates.
Why was this data collected?
Besides travel demand, Hans-Jörg’s survey also asks participants about their coffee consumption during train rides. Here’s how he tells the story behind the data:
As a nearly daily commuter I like to enjoy a hot coffee on my train rides. But what has bugged me for a long time is the fact the coffee or hot beverages in general are almost always served in a non-reusable, “one-use-only-and-then-throw-away” cup. So I ended up buying one of these mostly ugly and space-consuming reusable cups. Neither system seem to satisfy me as customer: the paper-cup produces a lot of waste, though it is convenient because I carry it only when I need it. With the re-usable cup I carry it all day even though most of the time it is empty and it is clumsy and consumes the limited space in bag.
So I have been looking for a system that gets rid of the disadvantages or rather provides the advantages of both approaches and I came up with the following idea: Installing a system that provides a re-usable cup that I only have with me when I need it.
In order to evaluate the potential for such a system – which would not only imply a material change of the cups in terms of hardware but also introduce some software solution with the convenience of getting back the necessary deposit that I pay as a customer and some software-solution in the back-end that handles all the cleaning, distribution to the different coffee-shops and managing a balanced stocking in the stations – I conducted a survey
The next step was the geographic visualization of the flow data and this is where QGIS comes into play.
The flow map
Survey data like the one described above is a common input for flow maps. There’s usually a point layer (here: “nodes”) that provides geographic information and a non-spatial layer (here: “edges”) that contains the information about the strength or weight of a flow between two specific nodes:
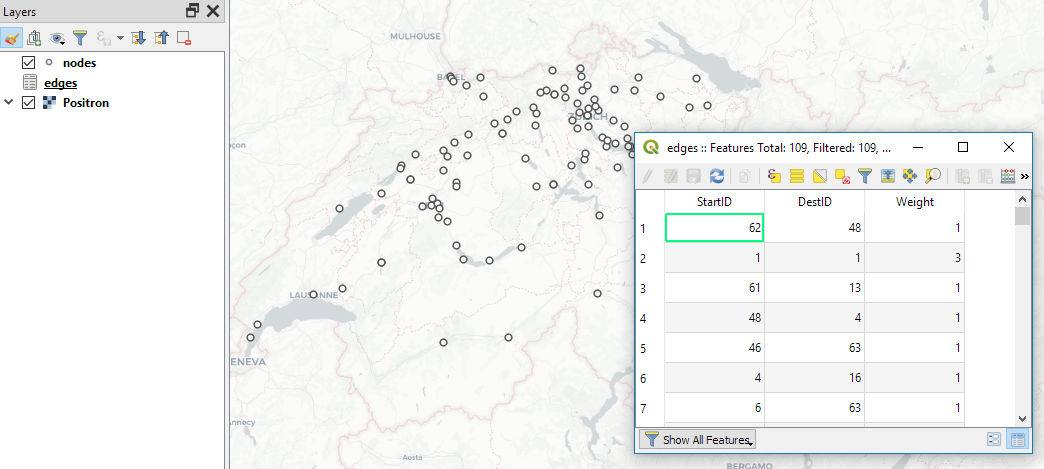
The first step therefore is to create the flow line features from the nodes and edges layers. To achieve our goal, we need to join both layers. Sounds like a job for SQL!
More specifically, this is a job for Virtual Layers: Layer | Add Layer | Add/Edit Virtual Layer
SELECT StartID, DestID, Weight,
make_line(a.geometry, b.geometry)
FROM edges
JOIN nodes a ON edges.StartID = a.ID
JOIN nodes b ON edges.DestID = b.ID
WHERE a.ID != b.ID
This SQL query joins the geographic information from the nodes table to the flow weights in the edges table based on the node IDs. In the last line, there is a check that start and end node ID should be different in order to avoid zero-length lines.
By styling the resulting flow lines using data-driven line width and adding in some feature blending, it’s possible to create some half decent maps:

However, we can definitely do better. Let’s throw in some curved arrows!
The arrow symbol layer type automatically creates curved arrows if the underlying line feature has three nodes that are not aligned on a straight line.
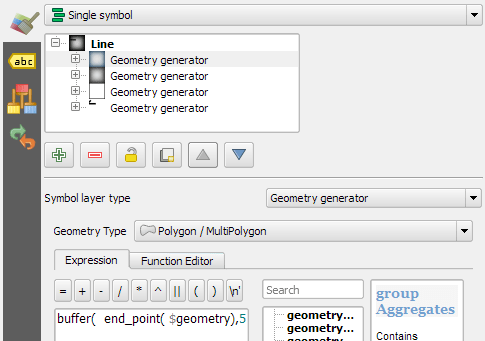
Therefore, to turn our straight lines into curved arrows, we need to add a third point to the line feature and it has to have an offset. This can be achieved using a geometry generator and the offset_curve() function:
make_line(
start_point($geometry),
centroid(
offset_curve(
$geometry,
length($geometry)/-5.0
)
),
end_point($geometry)
)
Additionally, to achieve the effect described in New style: flow map arrows, we extend the geometry generator to crop the lines at the beginning and end:
difference(
difference(
make_line(
start_point($geometry),
centroid(
offset_curve(
$geometry,
length($geometry)/-5.0
)
),
end_point($geometry)
),
buffer(start_point($geometry), 0.01)
),
buffer(end_point( $geometry), 0.01)
)
By applying data-driven arrow and arrow head sizes, we can transform the plain flow map above into a much more appealing map:

The two different arrow colors are another way to emphasize flow direction. In this case, orange arrows mark flows to the west, while blue flows point east.
CASE WHEN x(start_point($geometry)) - x(end_point($geometry)) < 0 THEN '#1f78b4' ELSE '#ff7f00' END
Conclusion
As you can see, virtual layers and geometry generators are a powerful combination. If you encounter performance problems with the virtual layer, it’s always possible to make it permanent by exporting it to a file. This will speed up any further visualization or analysis steps.