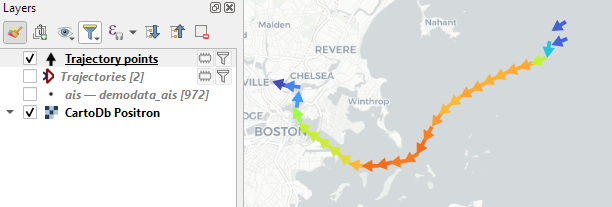
Today marks the release of Trajectools 2.3 which brings a new set of algorithms, including trajectory generalizing, cleaning, and smoothing.
To give you a quick impression of what some of these algorithms would be useful for, this post introduces a trajectory preprocessing workflow that is quite general-purpose and can be adapted to many different datasets.
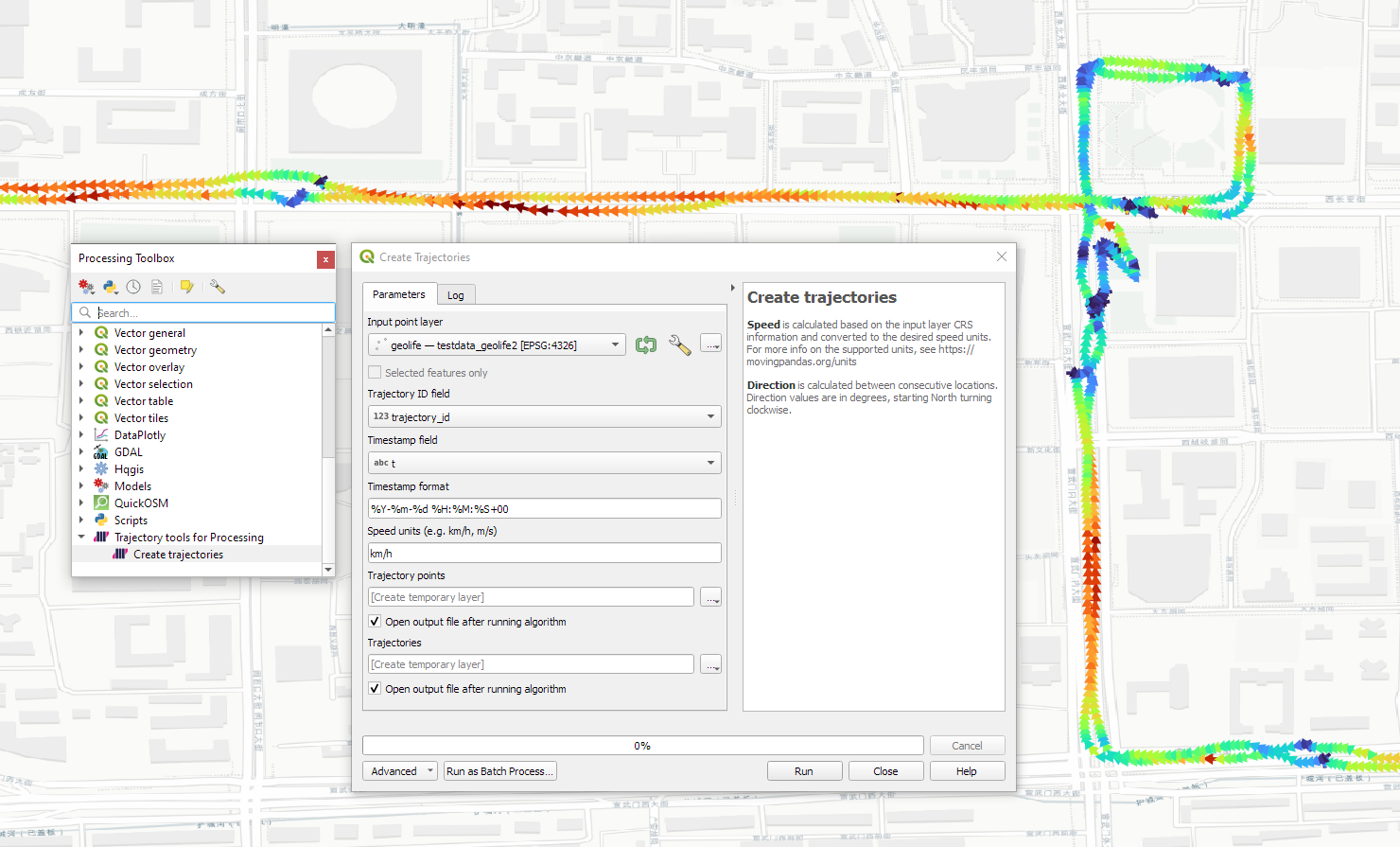
We start out with the Geolife sample dataset which you can find in the Trajectools plugin directory’s sample_data subdirectory. This small dataset includes 5908 points forming 5 trajectories, based on the trajectory_id field:
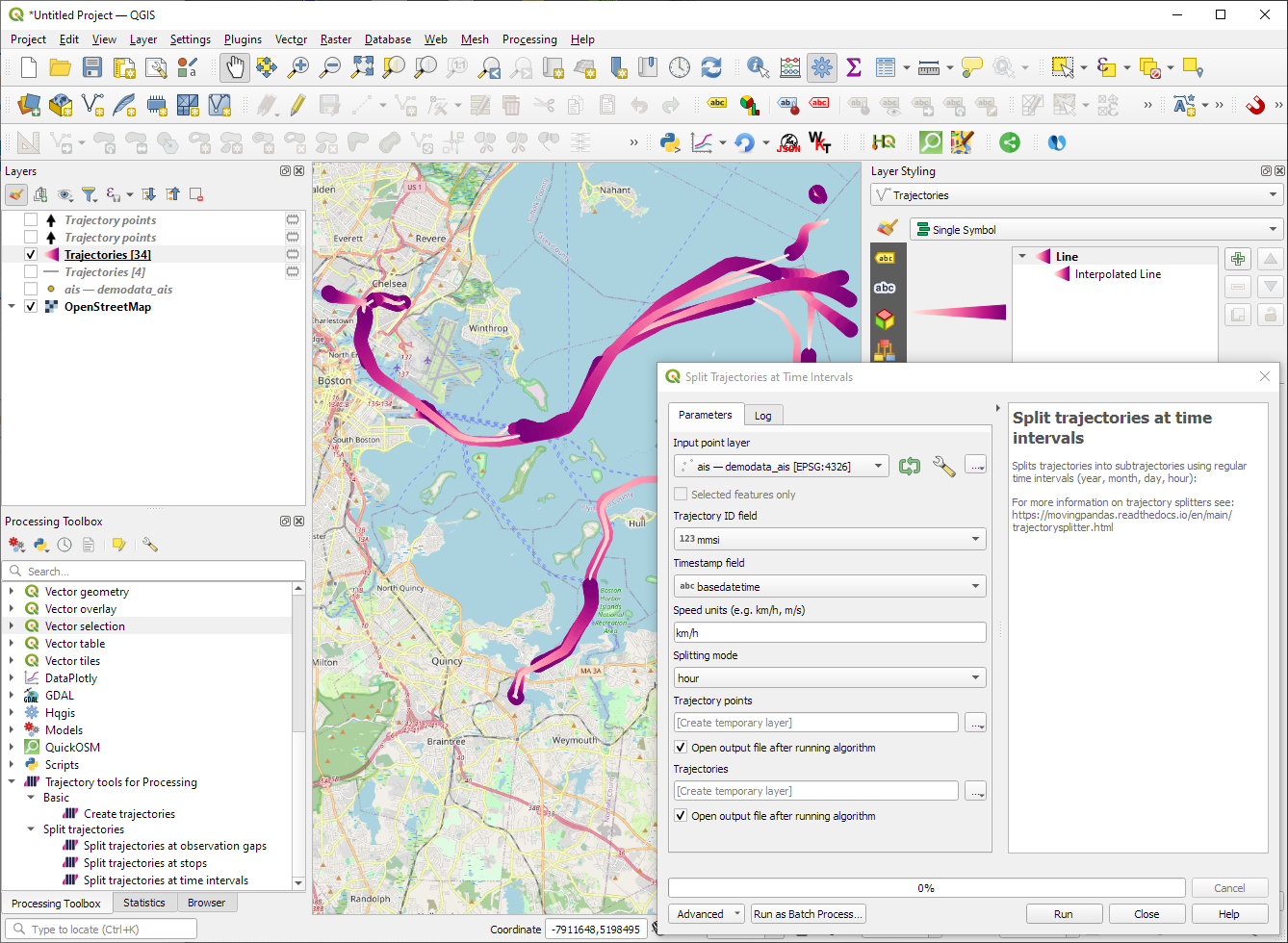
We first split our trajectories by observation gaps to ensure that there are no large gaps in our trajectories. Let’s make at cut at 15 minutes:
This splits the original 5 trajectories into 11 trajectories:
When we zoom, for example, to the two trajectories in the north western corner, we can see that the trajectories are pretty noisy and there’s even a spike / outlier at the western end:
If we label the points with the corresponding speeds, we can see how unrealistic they are: over 300 km/h!
Let’s remove outliers over 50 km/h:
Better but not perfect:
Let’s smooth the trajectories to get rid of more of the jittering.
(You’ll need to pip/mamba install the optional stonesoup library to get access to this algorithm.)
Depending on the noise values we chose, we get more or less smoothing:
Let’s zoom out to see the whole trajectory again:
Feel free to pan around and check how our preprocessing affected the other trajectories, for example:
If you downloaded Trajectools 2.1 and ran into troubles due to the introduced scikit-mobility and gtfs_functions dependencies, please update to Trajectools 2.2.
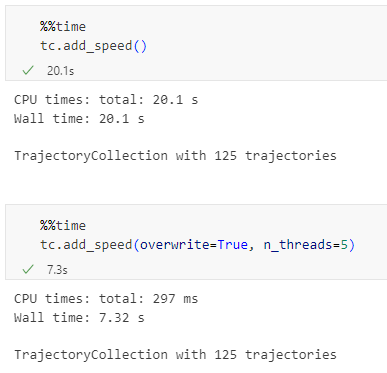
This new version makes it easier to set up Trajectools since MovingPandas is pip-installable on most systems nowadays and scikit-mobility and gtfs_functions are now truly optional dependencies. If you don’t install them, you simply will not see the extra algorithms they add:
If you encounter any other issues with Trajectools or have questions regarding its usage, please let me know in the Trajectools Discussions on Github.
Today marks the 2.1 release of Trajectools for QGIS. This release adds multiple new algorithms and improvements. Since some improvements involve upstream MovingPandas functionality, I recommend to also update MovingPandas while you’re at it.
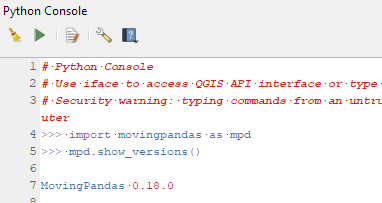
If you have installed QGIS and MovingPandas via conda / mamba, you can simply:
Afterwards, you can check that the library was correctly installed using:
import movingpandas as mpd mpd.show_versions()
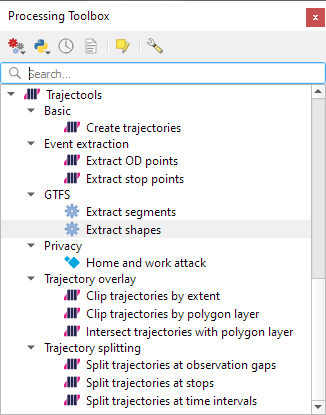
Trajectools 2.1
The new Trajectools algorithms are:
Trajectory overlay — Intersect trajectories with polygon layer
Privacy — Home work attack (requires scikit-mobility)
This algorithm determines how easy it is to identify an individual in a dataset. In a home and work attack the adversary knows the coordinates of the two locations most frequently visited by an individual.
Furthermore, we have fixed issue with previously ignored minimum trajectory length settings.
Scikit-mobility and gtfs_functions are optional dependencies. You do not need to install them, if you do not want to use the corresponding algorithms. In any case, they can be installed using mamba and pip:
There are a couple of existing plugins that deal with GTFS. However, in my experience, they either don’t integrate with Processing and/or don’t provide the functions I was expecting.
So far, we have two GTFS algorithms to cover essential public transport analysis needs:
The “Extract shapes” algorithm gives us the public transport routes:
The “Extract segments” algorithm has one more options. In addition to extracting the segments between public transport stops, it can also enrich the segments with the scheduled vehicle speeds:
Here you can see the scheduled speeds:
To show the stops, we can put marker line markers on the segment start and end locations:
The segments contain route information and stop names, so these can be extracted and used for labeling as well:
This is the first version without the “experimental” flag. If you look at the plugin release history, you will see that the previous release was from 2020. That’s quite a while ago and a lot has happened since, including the development of MovingPandas.
Let’s have a look what’s new!
The old “Trajectories from point layer”, “Add heading to points”, and “Add speed (m/s) to points” algorithms have been superseded by the new “Create trajectories” algorithm which automatically computes speeds and headings when creating the trajectory outputs.
“Day trajectories from point layer” is covered by the new “Split trajectories at time intervals” which supports splitting by hour, day, month, and year.
“Clip trajectories by extent” still exists but, additionally, we can now also “Clip trajectories by polygon layer”
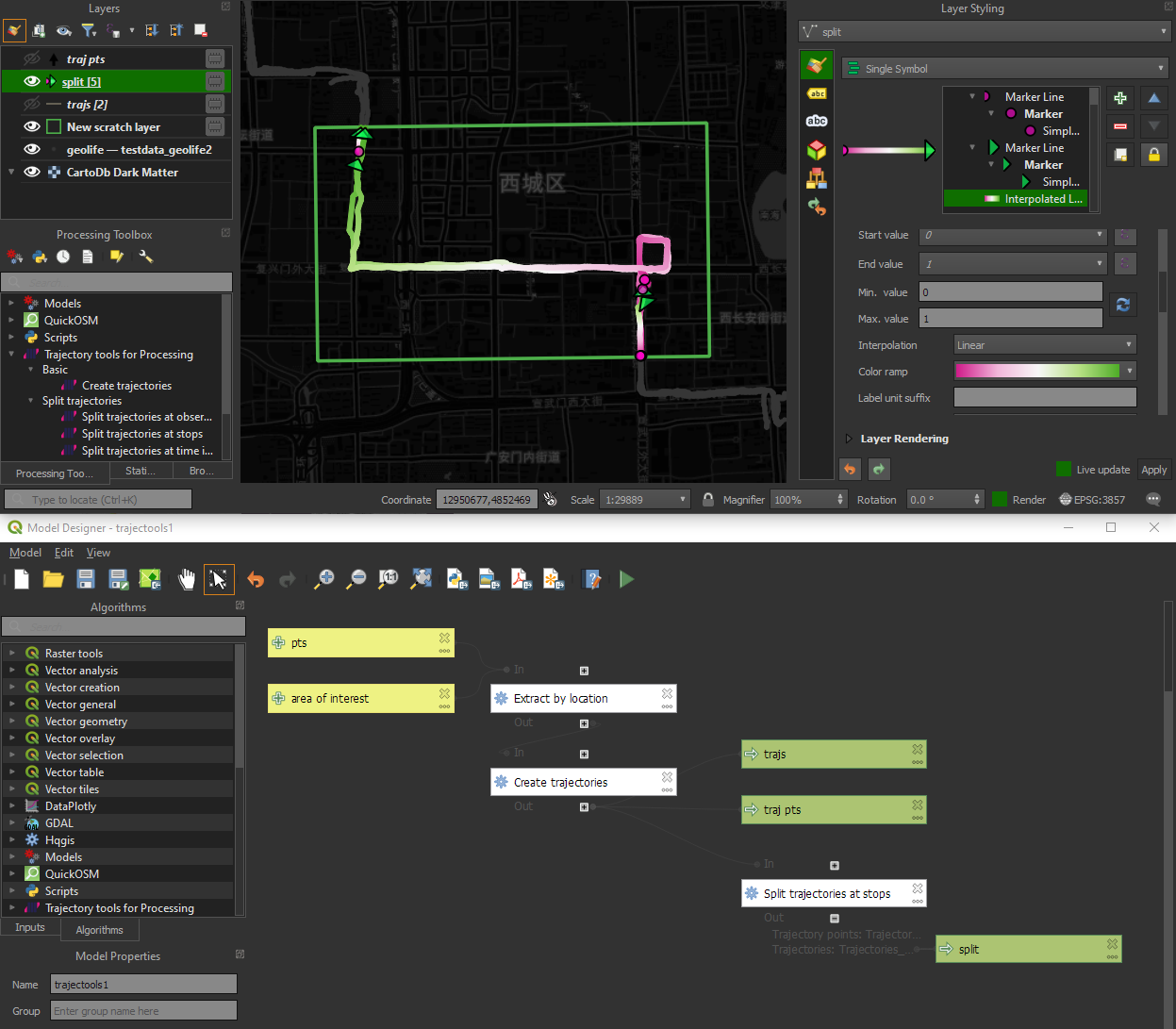
There are two new event extraction algorithms to “Extract OD points” and “Extract OD points”, as well as the related “Split trajectories at stops”. Additionally, we can also “Split trajectories at observation gaps”.
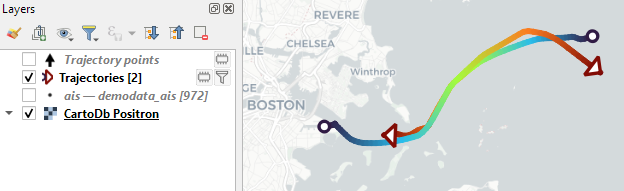
Trajectory outputs, by default, come as a pair of a point layer and a line layer. Depending on your use case, you can use both or pick just one of them. By default, the line layer is styled with a gradient line that makes it easy to see the movement direction:
while the default point layer style shows the movement speed:
How to use Trajectools
Trajectools 2.0 is powered by MovingPandas. You will need to install MovingPandas in your QGIS Python environment. I recommend installing both QGIS and MovingPandas from conda-forge:
The plugin download includes small trajectory sample datasets so you can get started immediately.
Outlook
There is still some work to do to reach feature parity with MovingPandas. Stay tuned for more trajectory algorithms, including but not limited to down-sampling, smoothing, and outlier cleaning.
I’m also reviewing other existing QGIS plugins to see how they can complement each other. If you know a plugin I should look into, please leave a note in the comments.
I’m continuously testing the algorithms integrated so far to see if they work as GIS users would expect and can to ensure that they can be integrated in Processing model seamlessly.
Because naming things is tricky, I’m currently struggling with how to best group the toolbox algorithms into meaningful categories. I looked into the categories mentioned in OGC Moving Features Access but honestly found them kind of lacking:
… but I’m not convinced yet. So take the above listed three categories with a grain of salt. Those may change before the release. (Any inputs / feedback / recommendation welcome!)
Let me close this quick status update with a screencast showcasing stop detection in AIS data, featuring the recently added trajectory styling using interpolated lines:
Trajectools development started back in 2018 but has been on hold since 2020 when I realized that it would be necessary to first develop a solid trajectory analysis library. With the MovingPandas library in place, I’ve now started to reboot Trajectools.
Trajectools v2 builds on MovingPandas and exposes its trajectory analysis algorithms in the QGIS Processing Toolbox. So far, I have integrated the basic steps of
Building trajectories including speed and direction information from timestamped points and
Splitting trajectories at observation gaps, stops, or regular time intervals.
The algorithms create two output layers:
Trajectory points with speed and direction information that are styled using arrow markers
Trajectories as LineStringMs which makes it straightforward to count the number of trajectories and to visualize where one trajectory ends and another starts.
So far, the default style for the trajectory points is hard-coded to apply the Turbo color ramp on the speed column with values from 0 to 50 (since I’m simply loading a ready-made QML). By default, the speed is calculated as km/h but that can be customized:
I don’t have a solution yet to automatically create a style for the trajectory lines layer. Ideally, the style should be a categorized renderer that assigns random colors based on the trajectory id column. But in this case, it’s not enough to just load a QML.
In the meantime, I might instead include an Interpolated Line style. What do you think?
Of course, the goal is to make Trajectools interoperable with as many existing QGIS Processing Toolbox algorithms as possible to enable efficient Mobility Data Science workflows.
The easiest way to set up QGIS with MovingPandas Python environment is to install both from conda. You can find the instructions together with the latest Trajectools development version at: https://github.com/movingpandas/qgis-processing-trajectory
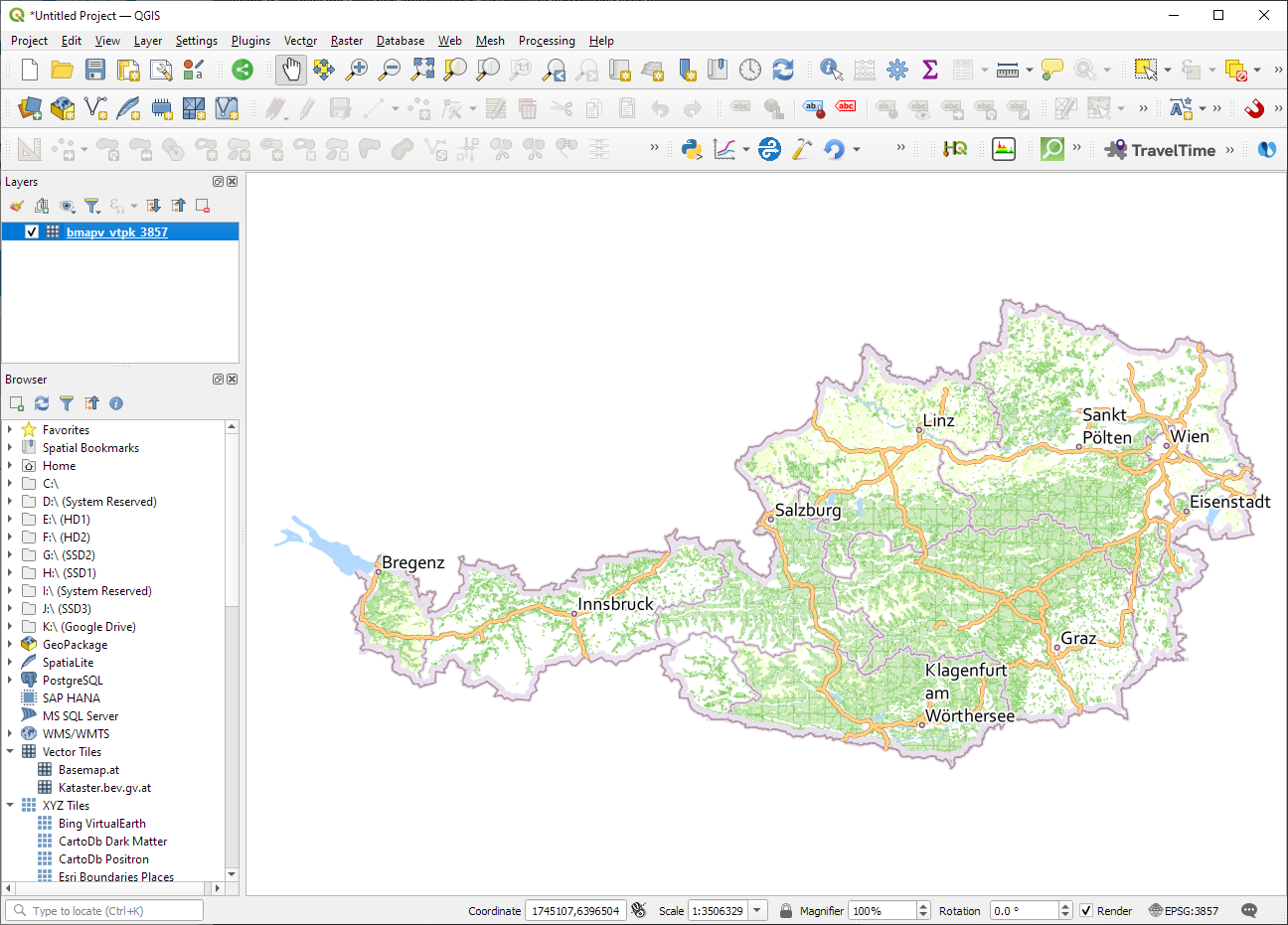
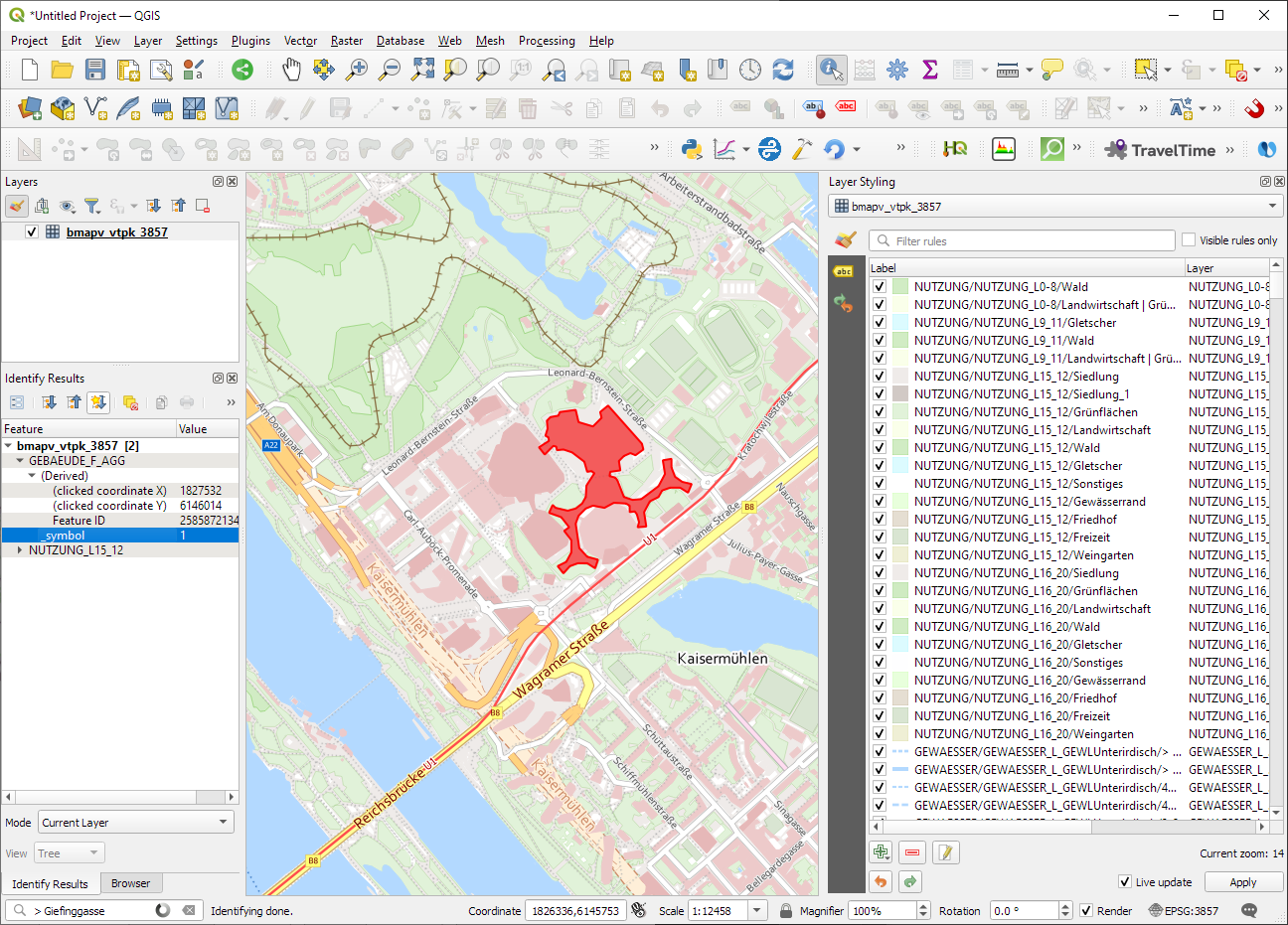
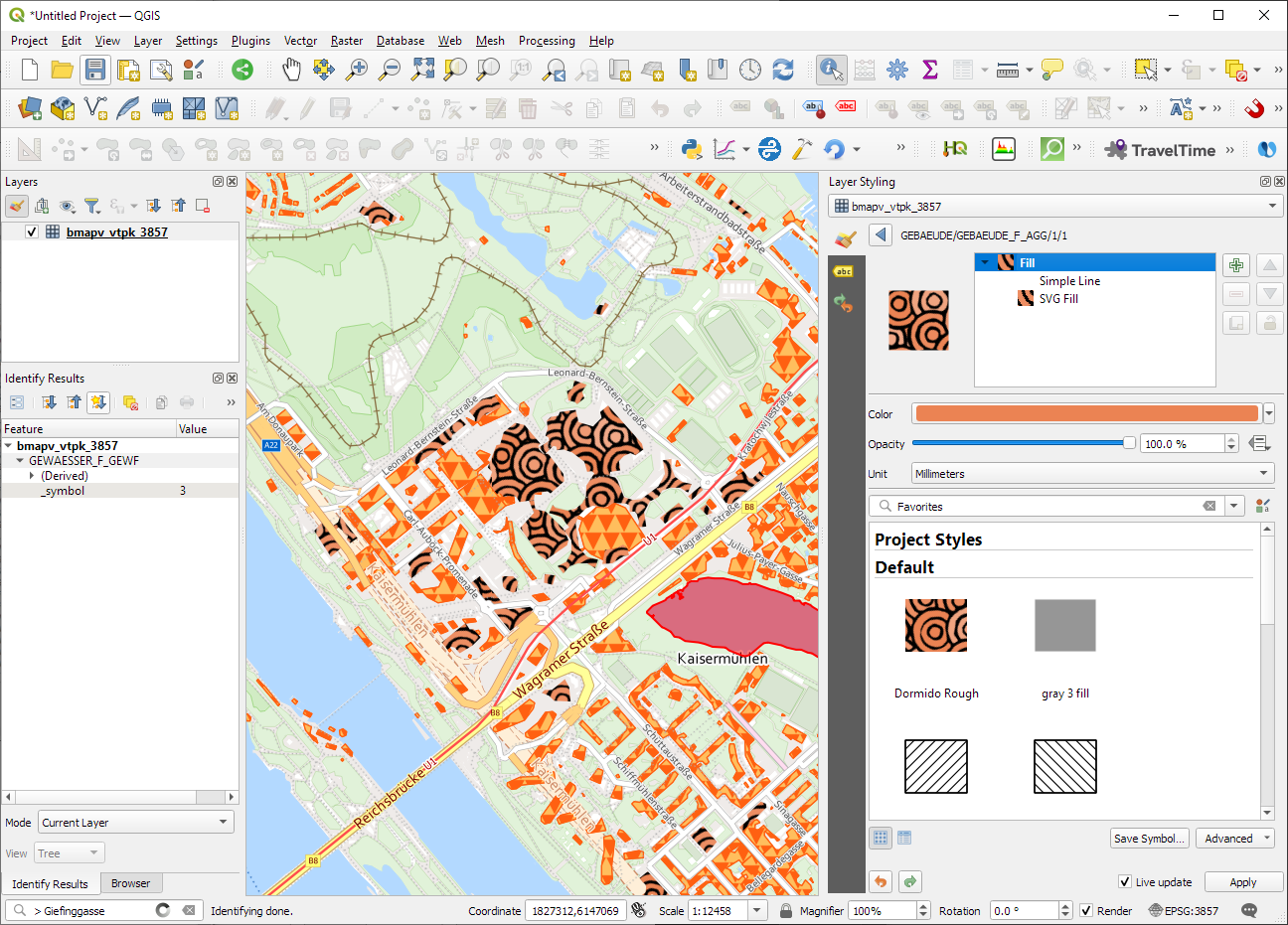
ESRI vector tile packages (VTPK files) can now be opened directly as vector tile layers via drag and drop, including support for style translation.
This is great news, particularly for users from Austria, since this makes it possible to use the open government basemap.at vector tiles directly, without any fuss:
Today, we’ll take the next step and add basemaps to our maps. This is trickier than I would have expected. In particular, I was fighting with “invalid” OSM tile layers until I realized that my QGIS application instance somehow lacked the “WMS” provider.
In addition, getting basemaps to work also means that we have to take care of layer and project CRSes and on-the-fly reprojections. So let’s get to work:
from IPython.display import Image
from PyQt5.QtGui import QColor
from PyQt5.QtWidgets import QApplication
from qgis.core import QgsApplication, QgsVectorLayer, QgsProject, QgsRasterLayer, \
QgsCoordinateReferenceSystem, QgsProviderRegistry, QgsSimpleMarkerSymbolLayerBase
from qgis.gui import QgsMapCanvas
app = QApplication([])
qgs = QgsApplication([], False)
qgs.setPrefixPath(r"C:\temp", True) # setting a prefix path should enable the WMS provider
qgs.initQgis()
canvas = QgsMapCanvas()
project = QgsProject.instance()
map_crs = QgsCoordinateReferenceSystem('EPSG:3857')
canvas.setDestinationCrs(map_crs)
print("providers: ", QgsProviderRegistry.instance().providerList())
To add an OSM basemap, we use the xyz tiles option of the WMS provider:
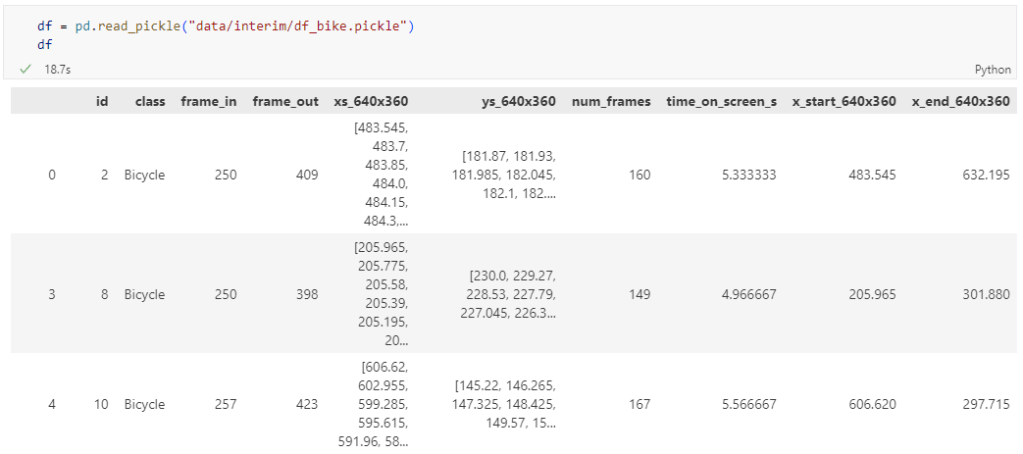
The bicycle trajectory coordinates are stored in two separate lists: xs_640x360 and ys640x360:
This format is kind of similar to the Kaggle Taxi dataset, we worked with in the previous post. However, to use the solution we implemented there, we need to combine the x and y coordinates into nice (x,y) tuples:
Afterwards, we can create the points and compute the proper timestamps from the frame numbers:
def compute_datetime(row):
# some educated guessing going on here: the paper states that the video covers 2021-06-09 07:00-08:00
d = datetime(2021,6,9,7,0,0) + (row['frame_in'] + row['running_number']) * timedelta(seconds=2)
return d
def create_point(xy):
try:
return Point(xy)
except TypeError: # when there are nan values in the input data
return None
new_df = df.head().explode('coordinates')
new_df['geometry'] = new_df['coordinates'].apply(create_point)
new_df['running_number'] = new_df.groupby('id').cumcount()
new_df['datetime'] = new_df.apply(compute_datetime, axis=1)
new_df.drop(columns=['coordinates', 'frame_in', 'running_number'], inplace=True)
new_df
Once the points and timestamps are ready, we can create the MovingPandas TrajectoryCollection. Note how we explicitly state that there is no CRS for this dataset (crs=None):
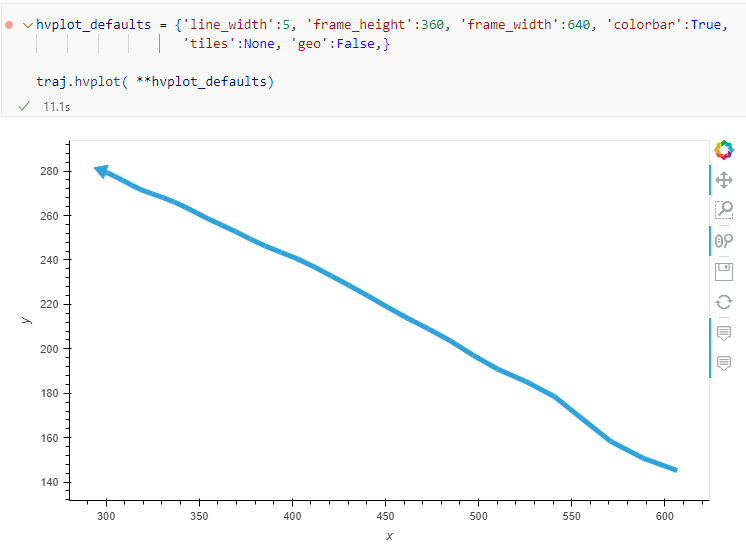
Similarly, to plot these trajectories, we should tell hvplot that it should not fetch any background map tiles (’tiles’:None) and that the coordinates are not geographic (‘geo’:False):
One important caveat is that speed will be calculated in pixels per second. So when we plot the bicycle speed, the segments closer to the camera will appear faster than the segments in the background:
To fix this issue, we would have to correct for the distortions of the camera lens and perspective. I’m sure that there is specialized software for this task but, for the purpose of this post, I’m going to grab the opportunity to finally test out the VectorBender plugin.
Georeferencing the trajectories using QGIS VectorBender plugin
Let’s load the five test trajectories and the camera image to QGIS. To make sure that they align properly, both are set to the same CRS and I’ve created the following basic world file for the camera image:
1
0
0
-1
0
360
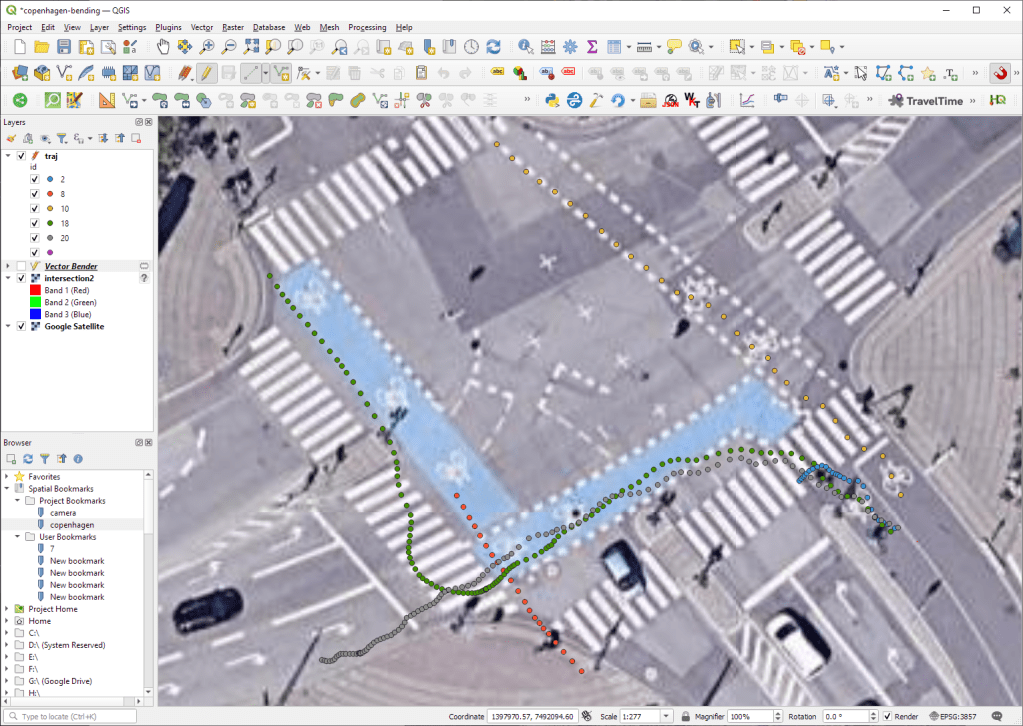
Then we can use the VectorBender tools to georeference the trajectories by linking locations from the camera image to locations on aerial images. You can see the whole process in action here:
After around 15 minutes linking control points, VectorBender comes up with the following georeferenced trajectory result:
Not bad for a quick-and-dirty hack. Some points on the borders of the image could not be georeferenced since I wasn’t always able to identify suitable control points at the camera image borders. So it won’t be perfect but should improve speed estimates.