Yesterday, I described my process to generate a basic population density map from the city of Vienna’s open government data. In the end of that post, I described some ideas for further improvement. Today, I want to follow-up on those ideas using what is known as dasymetric mapping. GIS Dictionary defines it well (much better than Wikipedia):
Dasymetric mapping is a technique in which attribute data that is organized by a large or arbitrary area unit is more accurately distributed within that unit by the overlay of geographic boundaries that exclude, restrict, or confine the attribute in question.
For example, a population attribute organized by census tract might be more accurately distributed by the overlay of water bodies, vacant land, and other land-use boundaries within which it is reasonable to infer that people do not live.
That’s exactly what I want to do: Based on subdistricts with population density values and auxiliary data – Corine Land Cover to be exact – I want to create an improved representation of population density within the city.
This is the population density map I start out with:

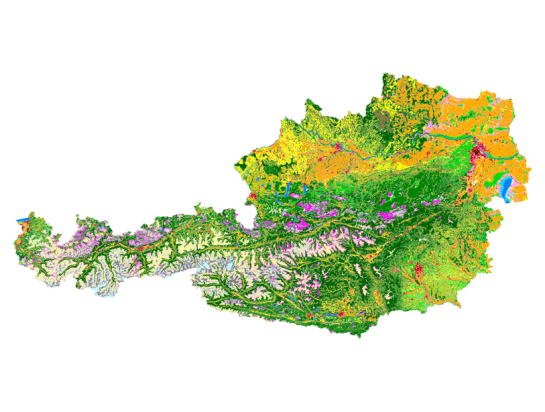
… and this is the Corine Land Cover dataset for the same area:

It shows built-up areas (red), parks and natural areas (green) as well as water-covered regions (blue). For further analysis, I follow the assumption that people only live in areas with Corine code 111 “Continuous urban fabric” and 112 “Discontinuous urban fabric”. Therefore, I use the Intersection tool to clip only these residential areas from the subdistrict polygons. The subdistrict population can now be distributed over these new, smaller areas (use Field Calculator) to create a more realistic visualization of population density:

For easier comparison, I put the original density and the dasymetric map into a looping animation. Some subdistricts change their population density values quite drastically, especially in regions where big parts covered by water or rail infrastructure were removed:

Corine Land Cover is not too detailed but I think it still usable on this scale. One thing to note is that I used data from 2006 with population data from 2012 so some areas in the outer districts will have been turned residential in the meantime. But I hope this doesn’t distort the overall picture too much.