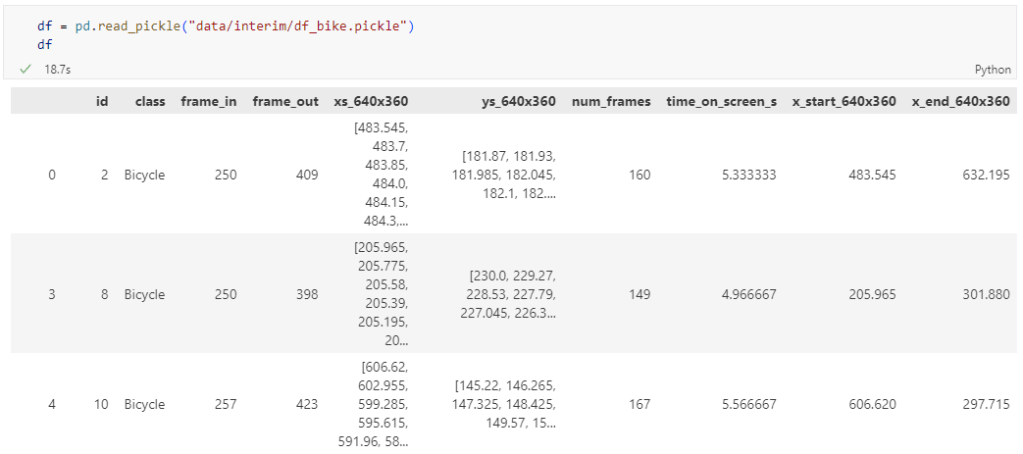
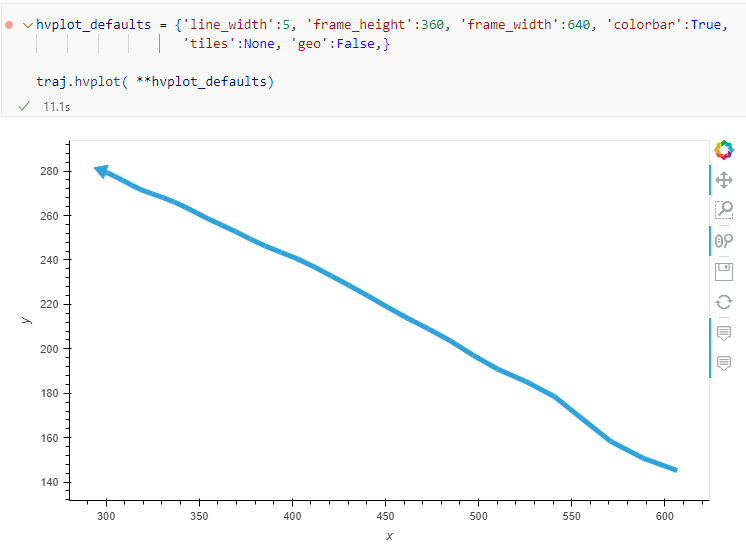
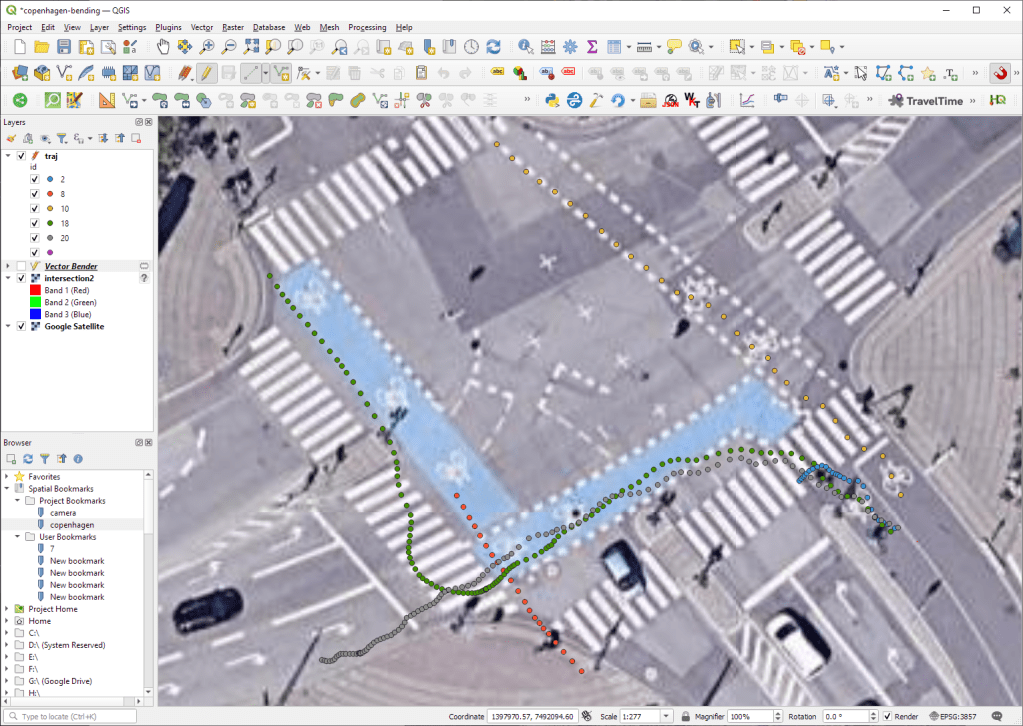
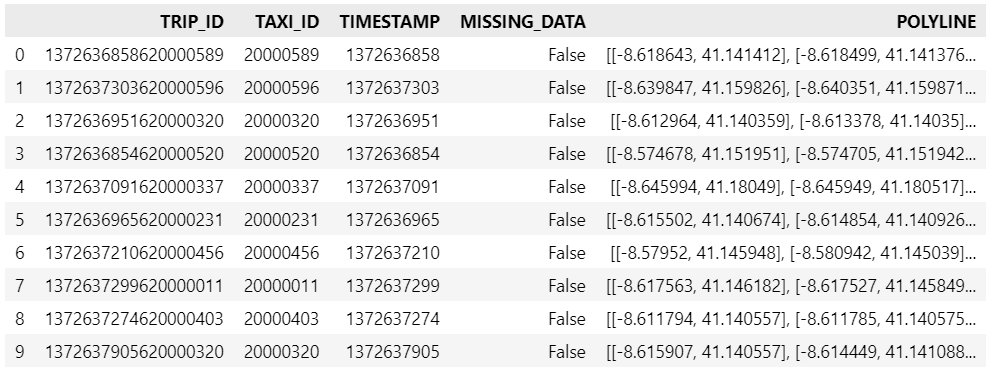
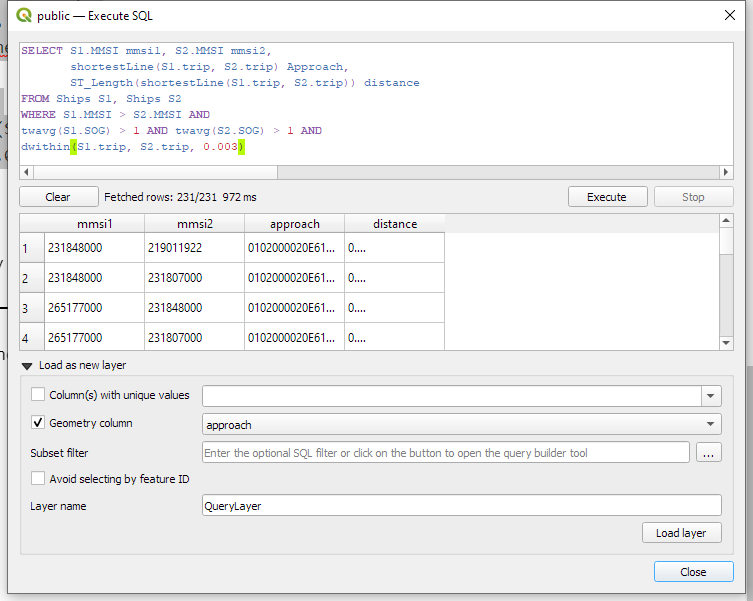
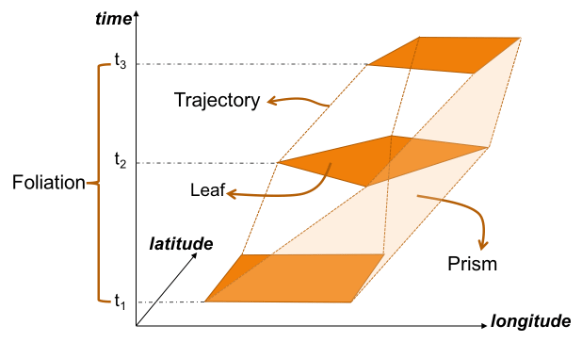
Today’s post is a first quick dive into Neo4J (really just getting my toes wet). It’s based on a publicly available Neo4J dump containing mobility data, ship trajectories to be specific. You can find this data and the setup instructions at:
I was made aware of this work since they cited MovingPandas in their paper in Data & Knowledge Engineering: “The implementation combines several open source tools such as Python, MovingPandas library, Uber H3 index, Neo4j graph database management system”
Once set up, this gives us a database with three hierarchical levels:

Neo4j comes with a nice graphical browser that lets us explore the data. We can switch between levels and click on individual node labels to get a quick preview:


Level 2 is a generalization / aggregation of level 1. Expanding the graph of one of the level 2 nodes shows its connection to level 1. For example, the level 2 port node “Audierne” actually refers to two level 1 nodes:

Every “road” level 1 relationship between ports provide information about the ship, its arrival, departure, travel time, and speed. We can see that this two level 1 ports must be pretty close since travel times are only 5 minutes:

Further expanding one of the port level 1 nodes shows its connection to waypoints of level1:

Switching to level 2, we gain access to nodes of type Traj(ectory). Additionally, the road level 2 relationships represent aggregations of the trajectories, for example, here’s a relationship with only one associated trajectory:

There are also some odd relationships, for example, trajectory 43 has two ends and begins relationships and there are also two road relationships referencing this trajectory (with identical information, only differing in their automatic <id>). I’m not yet sure if that is a feature or a bug:

On level 1, we also have access to ship nodes. They are connected to ports and waypoints. However, exploring them visually is challenging. Things look fine at first:

But after a while, once all relationships have loaded, we have it: the MIGHTY BALL OF YARN ™:

I guess this is the point where it becomes necessary to get accustomed to the query language. And no, it’s not SQL, it is Cypher. For example, selecting a specific trajectory with id 0, looks like this:
MATCH (t1 {traj_id: 0}) RETURN t1
But more on this another time.
This post is part of a series. Read more about movement data in GIS.