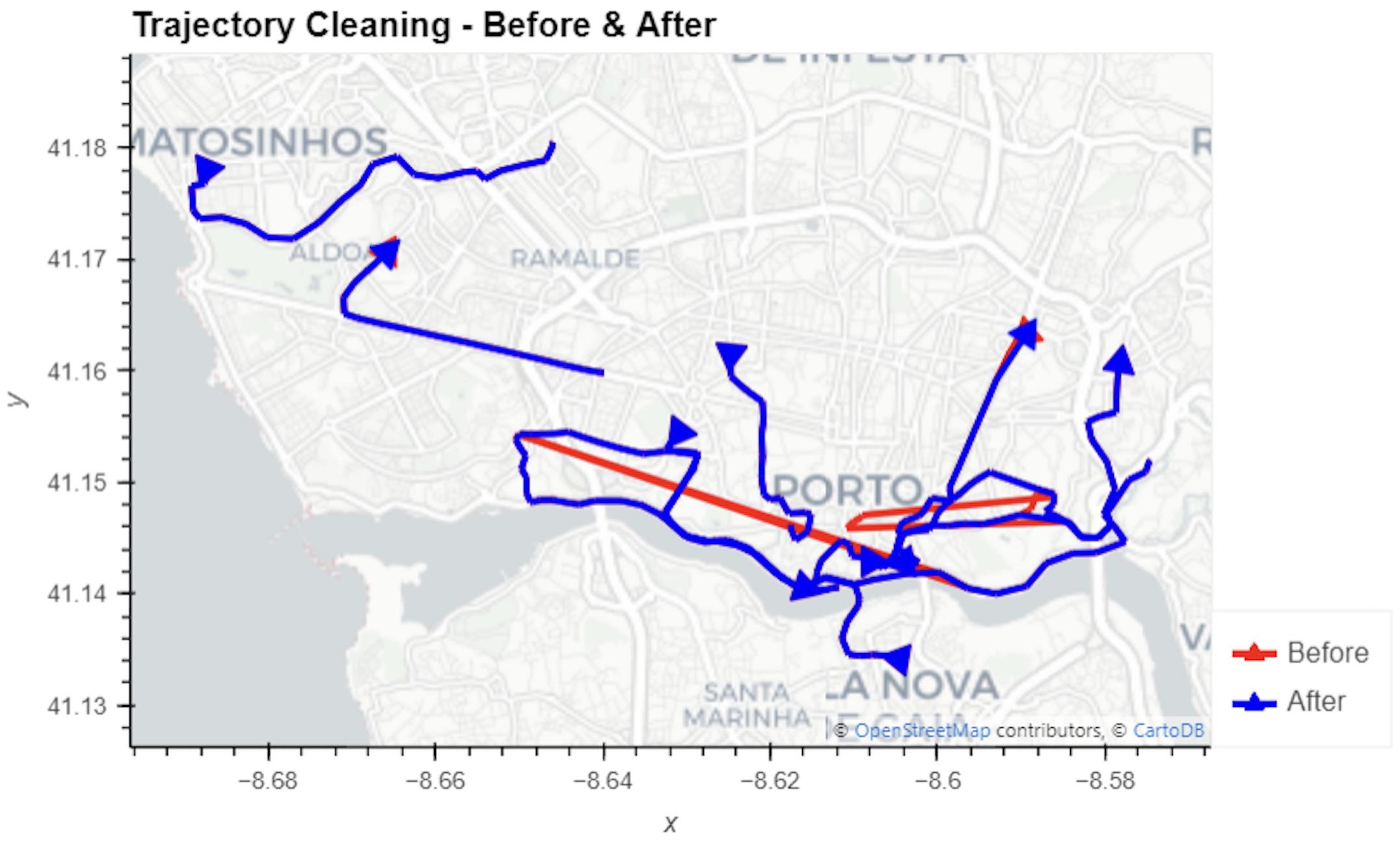
I’m continuously testing the algorithms integrated so far to see if they work as GIS users would expect and can to ensure that they can be integrated in Processing model seamlessly.
Because naming things is tricky, I’m currently struggling with how to best group the toolbox algorithms into meaningful categories. I looked into the categories mentioned in OGC Moving Features Access but honestly found them kind of lacking:
… but I’m not convinced yet. So take the above listed three categories with a grain of salt. Those may change before the release. (Any inputs / feedback / recommendation welcome!)
Let me close this quick status update with a screencast showcasing stop detection in AIS data, featuring the recently added trajectory styling using interpolated lines:
written together with my fellow co-authors and EMERALDS project team members Argyrios Kyrgiazos and Helen McKenzie.
In this blog post, we walk you through a trajectory hotspot analysis using open taxi trajectory data from Kaggle, combining data preparation with MovingPandas (including the new OutlierCleaner illustrated above) and spatiotemporal hotspot analysis from Carto.
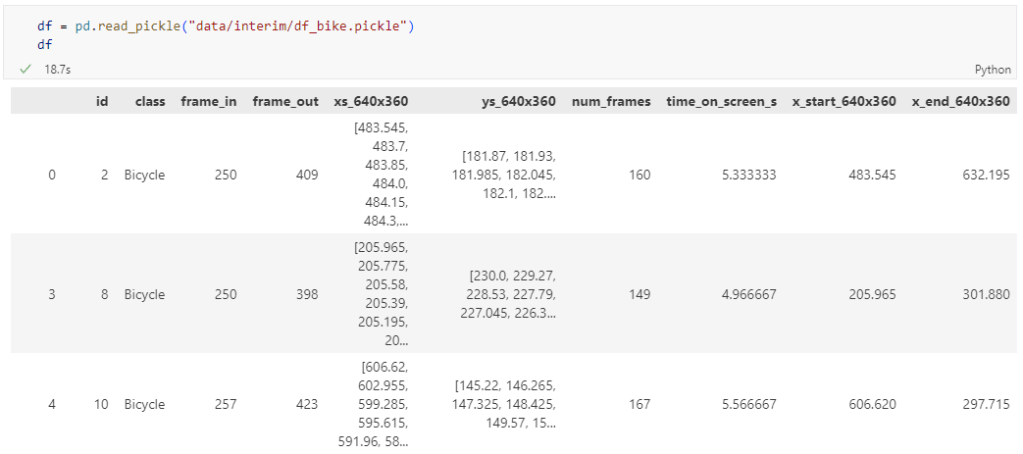
The bicycle trajectory coordinates are stored in two separate lists: xs_640x360 and ys640x360:
This format is kind of similar to the Kaggle Taxi dataset, we worked with in the previous post. However, to use the solution we implemented there, we need to combine the x and y coordinates into nice (x,y) tuples:
Afterwards, we can create the points and compute the proper timestamps from the frame numbers:
def compute_datetime(row):
# some educated guessing going on here: the paper states that the video covers 2021-06-09 07:00-08:00
d = datetime(2021,6,9,7,0,0) + (row['frame_in'] + row['running_number']) * timedelta(seconds=2)
return d
def create_point(xy):
try:
return Point(xy)
except TypeError: # when there are nan values in the input data
return None
new_df = df.head().explode('coordinates')
new_df['geometry'] = new_df['coordinates'].apply(create_point)
new_df['running_number'] = new_df.groupby('id').cumcount()
new_df['datetime'] = new_df.apply(compute_datetime, axis=1)
new_df.drop(columns=['coordinates', 'frame_in', 'running_number'], inplace=True)
new_df
Once the points and timestamps are ready, we can create the MovingPandas TrajectoryCollection. Note how we explicitly state that there is no CRS for this dataset (crs=None):
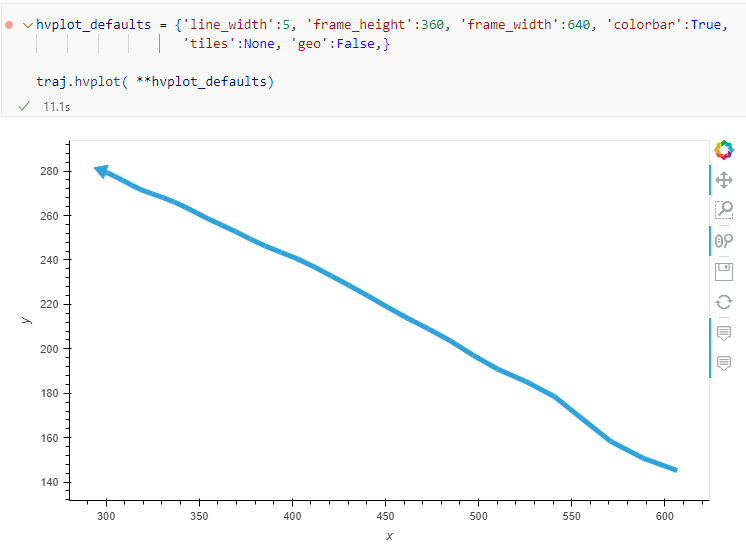
Similarly, to plot these trajectories, we should tell hvplot that it should not fetch any background map tiles (’tiles’:None) and that the coordinates are not geographic (‘geo’:False):
One important caveat is that speed will be calculated in pixels per second. So when we plot the bicycle speed, the segments closer to the camera will appear faster than the segments in the background:
To fix this issue, we would have to correct for the distortions of the camera lens and perspective. I’m sure that there is specialized software for this task but, for the purpose of this post, I’m going to grab the opportunity to finally test out the VectorBender plugin.
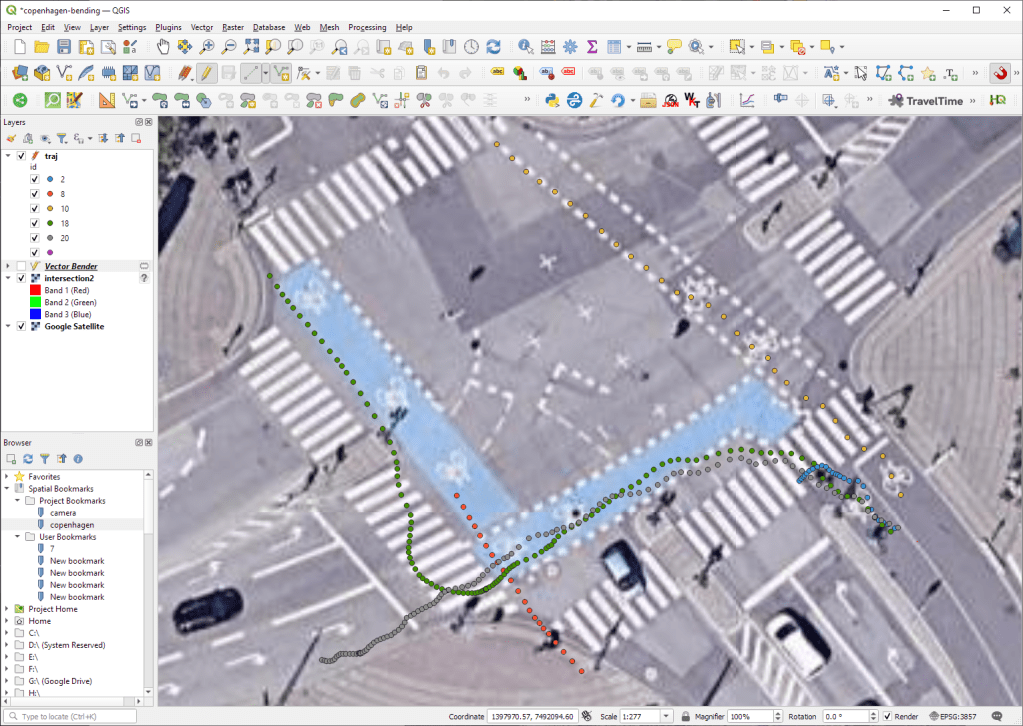
Georeferencing the trajectories using QGIS VectorBender plugin
Let’s load the five test trajectories and the camera image to QGIS. To make sure that they align properly, both are set to the same CRS and I’ve created the following basic world file for the camera image:
1
0
0
-1
0
360
Then we can use the VectorBender tools to georeference the trajectories by linking locations from the camera image to locations on aerial images. You can see the whole process in action here:
After around 15 minutes linking control points, VectorBender comes up with the following georeferenced trajectory result:
Not bad for a quick-and-dirty hack. Some points on the borders of the image could not be georeferenced since I wasn’t always able to identify suitable control points at the camera image borders. So it won’t be perfect but should improve speed estimates.
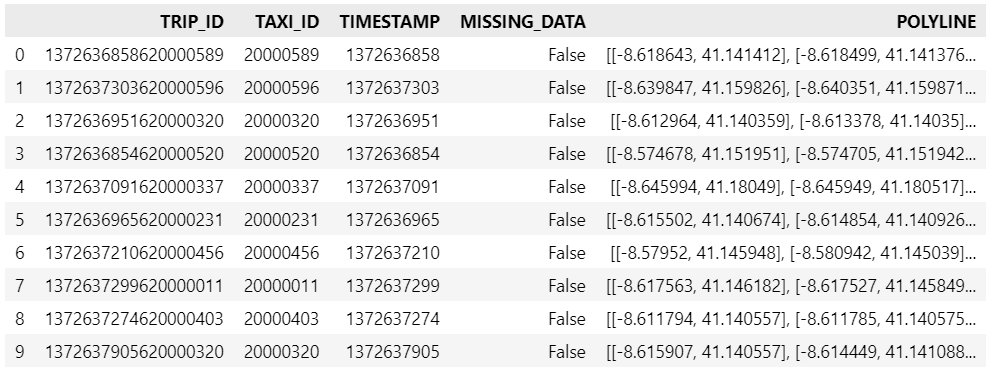
Kaggle’s “Taxi Trajectory Data from ECML/PKDD 15: Taxi Trip Time Prediction (II) Competition” is one of the most used mobility / vehicle trajectory datasets in computer science. However, in contrast to other similar datasets, Kaggle’s taxi trajectories are provided in a format that is not readily usable in MovingPandas since the spatiotemporal information is provided as:
TIMESTAMP: (integer) Unix Timestamp (in seconds). It identifies the trip’s start;
POLYLINE: (String): It contains a list of GPS coordinates (i.e. WGS84 format) mapped as a string. The beginning and the end of the string are identified with brackets (i.e. [ and ], respectively). Each pair of coordinates is also identified by the same brackets as [LONGITUDE, LATITUDE]. This list contains one pair of coordinates for each 15 seconds of trip. The last list item corresponds to the trip’s destination while the first one represents its start;
Therefore, we need to create a DataFrame with one point + timestamp per row before we can use MovingPandas to create Trajectories and analyze them.
But first things first. Let’s download the dataset:
import datetime
import pandas as pd
import geopandas as gpd
import movingpandas as mpd
import opendatasets as od
from os.path import exists
from shapely.geometry import Point
input_file_path = 'taxi-trajectory/train.csv'
def get_porto_taxi_from_kaggle():
if not exists(input_file_path):
od.download("https://www.kaggle.com/datasets/crailtap/taxi-trajectory")
get_porto_taxi_from_kaggle()
df = pd.read_csv(input_file_path, nrows=10, usecols=['TRIP_ID', 'TAXI_ID', 'TIMESTAMP', 'MISSING_DATA', 'POLYLINE'])
df.POLYLINE = df.POLYLINE.apply(eval) # string to list
df
And now for the remodelling:
def unixtime_to_datetime(unix_time):
return datetime.datetime.fromtimestamp(unix_time)
def compute_datetime(row):
unix_time = row['TIMESTAMP']
offset = row['running_number'] * datetime.timedelta(seconds=15)
return unixtime_to_datetime(unix_time) + offset
def create_point(xy):
try:
return Point(xy)
except TypeError: # when there are nan values in the input data
return None
new_df = df.explode('POLYLINE')
new_df['geometry'] = new_df['POLYLINE'].apply(create_point)
new_df['running_number'] = new_df.groupby('TRIP_ID').cumcount()
new_df['datetime'] = new_df.apply(compute_datetime, axis=1)
new_df.drop(columns=['POLYLINE', 'TIMESTAMP', 'running_number'], inplace=True)
new_df
And that’s it. Now we can create the trajectories:
That’s it. Now our MovingPandas.TrajectoryCollection is ready for further analysis.
By the way, the plot above illustrates a new feature in the recent MovingPandas 0.16 release which, among other features, introduced plots with arrow markers that show the movement direction. Other new features include a completely new custom distance, speed, and acceleration unit support. This means that, for example, instead of always getting speed in meters per second, you can now specify your desired output units, including km/h, mph, or nm/h (knots).
In the previous post, we — creatively ;-) — used MobilityDB to visualize stationary IOT sensor measurements.
This post covers the more obvious use case of visualizing trajectories. Thus bringing together the MobilityDB trajectories created in Detecting close encounters using MobilityDB 1.0 and visualization using Temporal Controller.
Like in the previous post, the valueAtTimestamp function does the heavy lifting. This time, we also apply it to the geometry time series column called trip:
Today’s post presents an experiment in modelling a common scenario in many IOT setups: time series of measurements at stationary sensors. The key idea I want to explore is to use MobilityDB’s temporal data types, in particular the tfloat_inst and tfloat_seq for instances and sequences of temporal float values, respectively.
For info on how to set up MobilityDB, please check my previous post.
Setting up our DB tables
As a toy example, let’s create two IOT devices (in table iot_devices) with three measurements each (in table iot_measurements) and join them to create the tfloat_seq (in table iot_joined):
CREATE TABLE iot_devices (
id integer,
geom geometry(Point, 4326)
);
INSERT INTO iot_devices (id, geom) VALUES
(1, ST_SetSRID(ST_MakePoint(1,1), 4326)),
(2, ST_SetSRID(ST_MakePoint(2,3), 4326));
CREATE TABLE iot_measurements (
device_id integer,
t timestamp,
measurement float
);
INSERT INTO iot_measurements (device_id, t, measurement) VALUES
(1, '2022-10-01 12:00:00', 5.0),
(1, '2022-10-01 12:01:00', 6.0),
(1, '2022-10-01 12:02:00', 10.0),
(2, '2022-10-01 12:00:00', 9.0),
(2, '2022-10-01 12:01:00', 6.0),
(2, '2022-10-01 12:02:00', 1.5);
CREATE TABLE iot_joined AS
SELECT
dev.id,
dev.geom,
tfloat_seq(array_agg(
tfloat_inst(m.measurement, m.t) ORDER BY t
)) measurements
FROM iot_devices dev
JOIN iot_measurements m
ON dev.id = m.device_id
GROUP BY dev.id, dev.geom;
We can load the resulting layer in QGIS but QGIS won’t be happy about the measurements column because it does not recognize its data type:
Query layer with valueAtTimestamp
Instead, what we can do is create a query layer that fetches the measurement value at a specific timestamp:
SELECT id, geom,
valueAtTimestamp(measurements, '2022-10-01 12:02:00')
FROM iot_joined
Which gives us a layer that QGIS is happy with:
Time for TemporalController
Now the tricky question is: how can we wire our query layer to the Temporal Controller so that we can control the timestamp and animate the layer?
I don’t have a GUI solution yet but here’s a way to do it with PyQGIS: whenever the Temporal Controller signal updateTemporalRange is emitted, our update_query_layer function gets the current time frame start time and replaces the datetime in the query layer’s data source with the current time:
l = iface.activeLayer()
tc = iface.mapCanvas().temporalController()
def update_query_layer():
tct = tc.dateTimeRangeForFrameNumber(tc.currentFrameNumber()).begin().toPyDateTime()
s = l.source()
new = re.sub(r"(\d{4})-(\d{2})-(\d{2}) (\d{2}):(\d{2}):(\d{2})", str(tct), s)
l.setDataSource(new, l.sourceName(), l.dataProvider().name())
tc.updateTemporalRange.connect(update_query_layer)
Future experiments will have to show how this approach performs on lager datasets but it’s exciting to see how MobilityDB’s temporal types may be visualized in QGIS without having to create tables/views that join a geometry to each and every individual measurement.
It’s been a while since we last talked about MobilityDB in 2019 and 2020. Since then, the project has come a long way. It joined OSGeo as a community project and formed a first PSC, including the project founders Mahmoud Sakr and Esteban Zimányi as well as Vicky Vergara (of pgRouting fame) and yours truly.
This post is a quick teaser tutorial from zero to computing closest points of approach (CPAs) between trajectories using MobilityDB.
Setting up MobilityDB with Docker
The easiest way to get started with MobilityDB is to use the ready-made Docker container provided by the project. I’m using Docker and WSL (Windows Subsystem Linux on Windows 10) here. Installing WLS/Docker is out of scope of this post. Please refer to the official documentation for your operating system.
Once Docker is ready, we can pull the official container and fire it up:
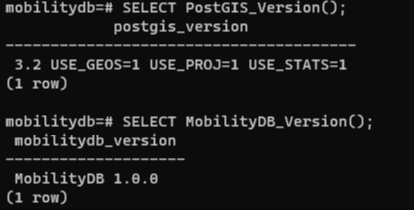
Currently, the container provides PostGIS 3.2 and MobilityDB 1.0:
Loading movement data into MobilityDB
Once the container is running, we can already connect to it from QGIS. This is my preferred way to load data into MobilityDB because we can simply drag-and-drop any timestamped point layer into the database:
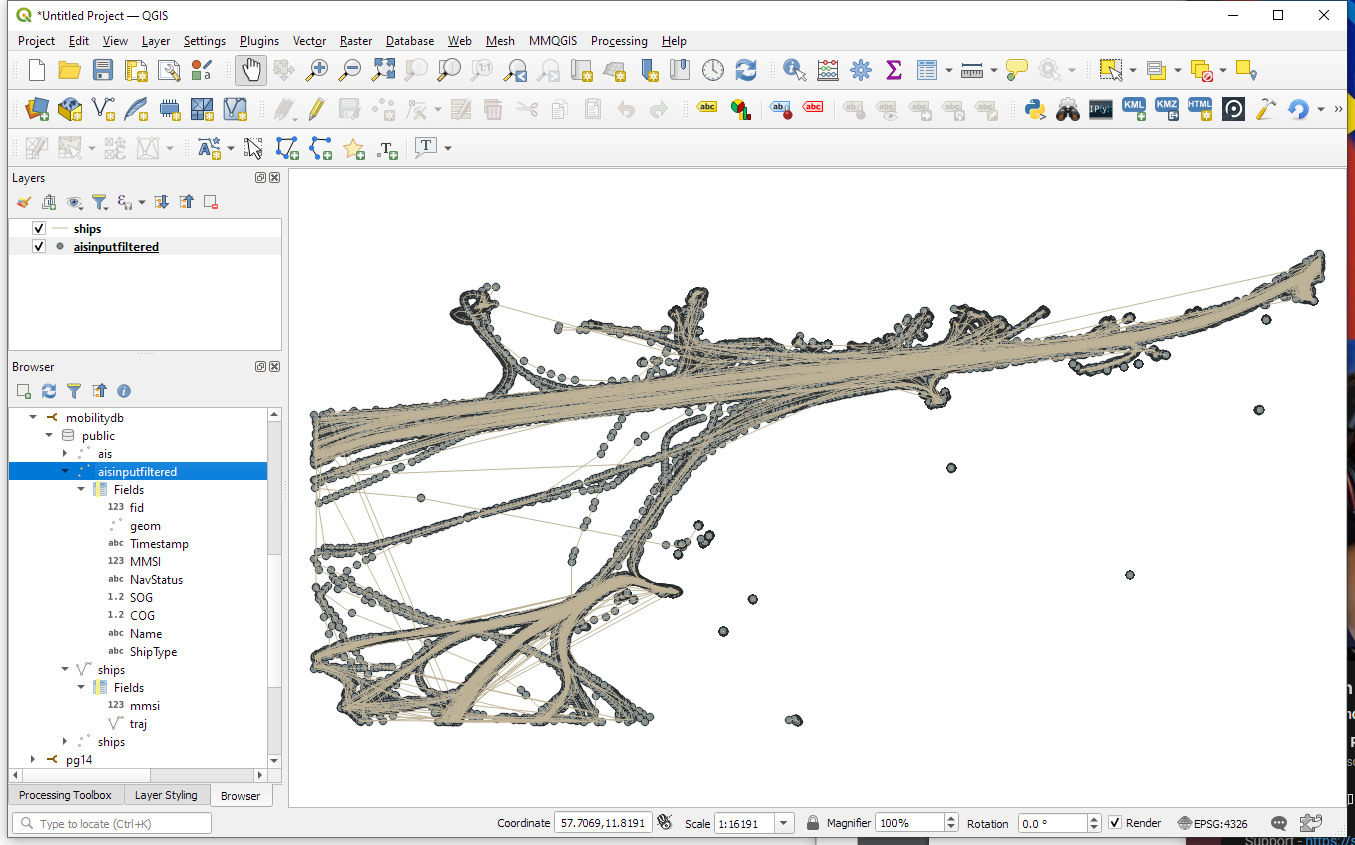
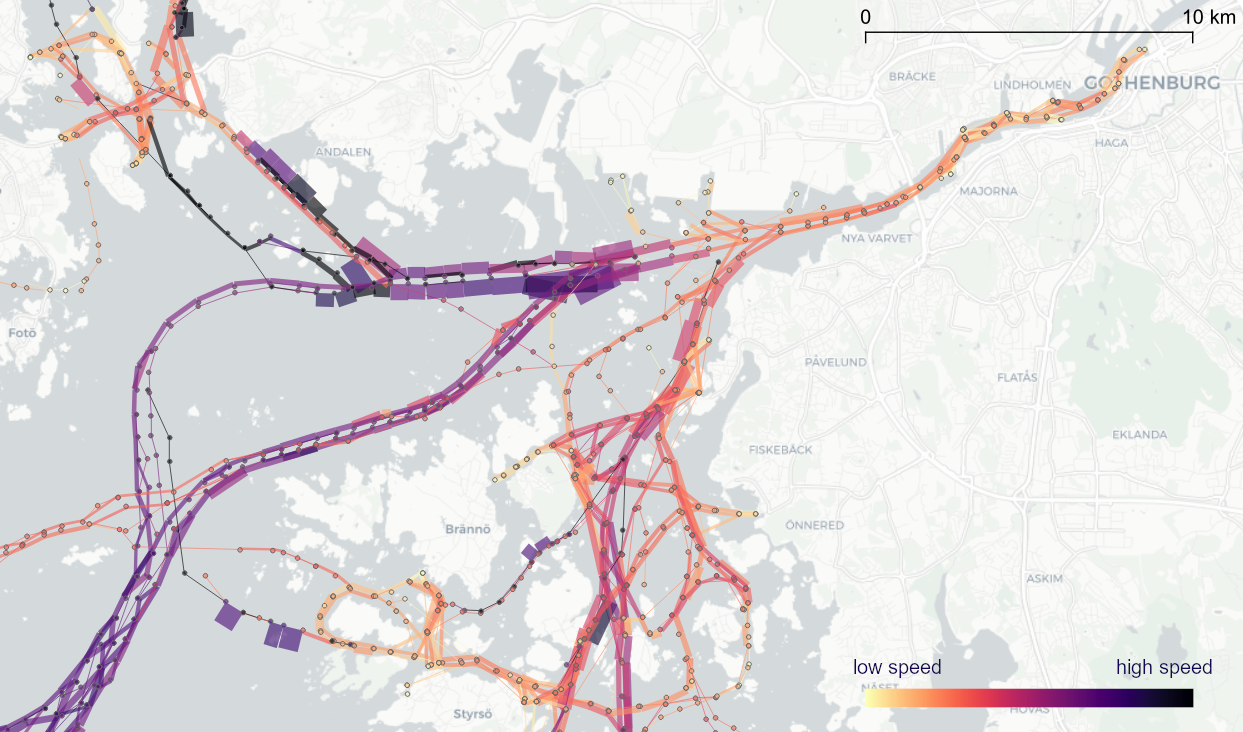
For this post, I’m using an AIS data sample in the region of Gothenburg, Sweden.
After loading this data into a new table called ais, it is necessary to remove duplicate and convert timestamps:
CREATE TABLE AISInputFiltered AS
SELECT DISTINCT ON("MMSI","Timestamp") *
FROM ais;
ALTER TABLE AISInputFiltered ADD COLUMN t timestamp;
UPDATE AISInputFiltered SET t = "Timestamp"::timestamp;
Afterwards, we can create the MobilityDB trajectories:
CREATE TABLE Ships AS
SELECT "MMSI" mmsi,
tgeompoint_seq(array_agg(tgeompoint_inst(Geom, t) ORDER BY t)) AS Trip,
tfloat_seq(array_agg(tfloat_inst("SOG", t) ORDER BY t) FILTER (WHERE "SOG" IS NOT NULL) ) AS SOG,
tfloat_seq(array_agg(tfloat_inst("COG", t) ORDER BY t) FILTER (WHERE "COG" IS NOT NULL) ) AS COG
FROM AISInputFiltered
GROUP BY "MMSI";
ALTER TABLE Ships ADD COLUMN Traj geometry;
UPDATE Ships SET Traj = trajectory(Trip);
Once this is done, we can load the resulting Ships layer and the trajectories will be loaded as lines:
Computing closest points of approach
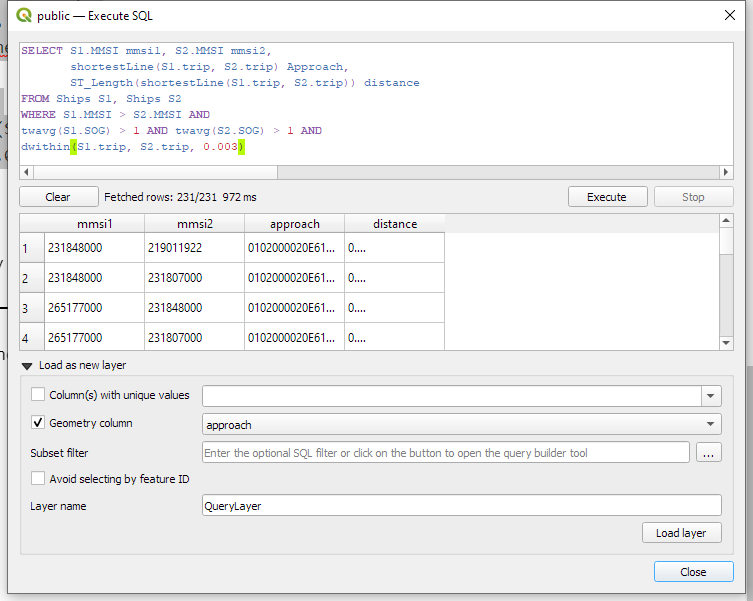
To compute the closest point of approach between two moving objects, MobilityDB provides a shortestLine function. To be correct, this function computes the line connecting the nearest approach point between the two tgeompoint_seq. In addition, we can use the time-weighted average function twavg to compute representative average movement speeds and eliminate stationary or very slowly moving objects:
SELECT S1.MMSI mmsi1, S2.MMSI mmsi2,
shortestLine(S1.trip, S2.trip) Approach,
ST_Length(shortestLine(S1.trip, S2.trip)) distance
FROM Ships S1, Ships S2
WHERE S1.MMSI > S2.MMSI AND
twavg(S1.SOG) > 1 AND twavg(S2.SOG) > 1 AND
dwithin(S1.trip, S2.trip, 0.003)
In the QGIS Browser panel, we can right-click the MobilityDB connection to bring up an SQL input using Execute SQL:
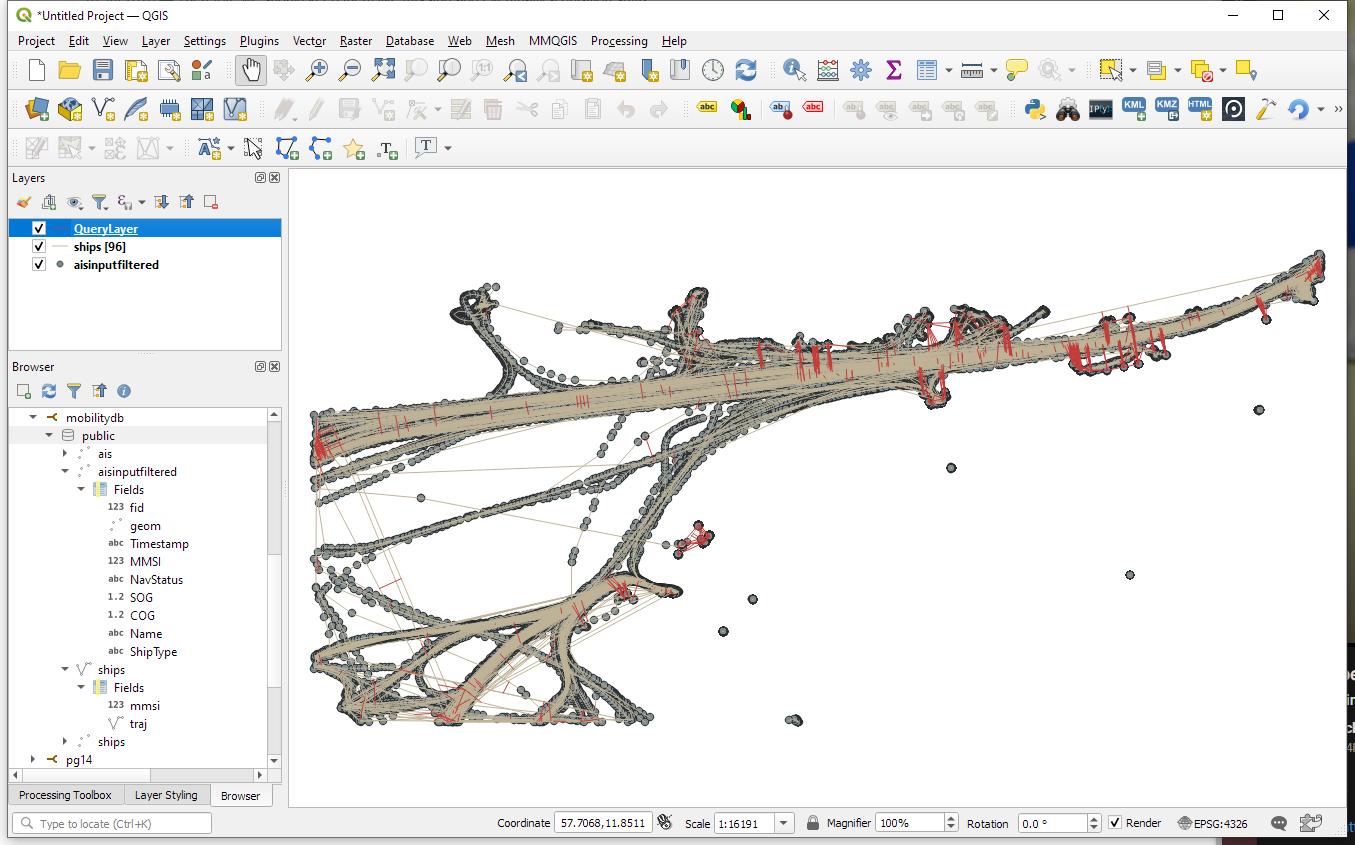
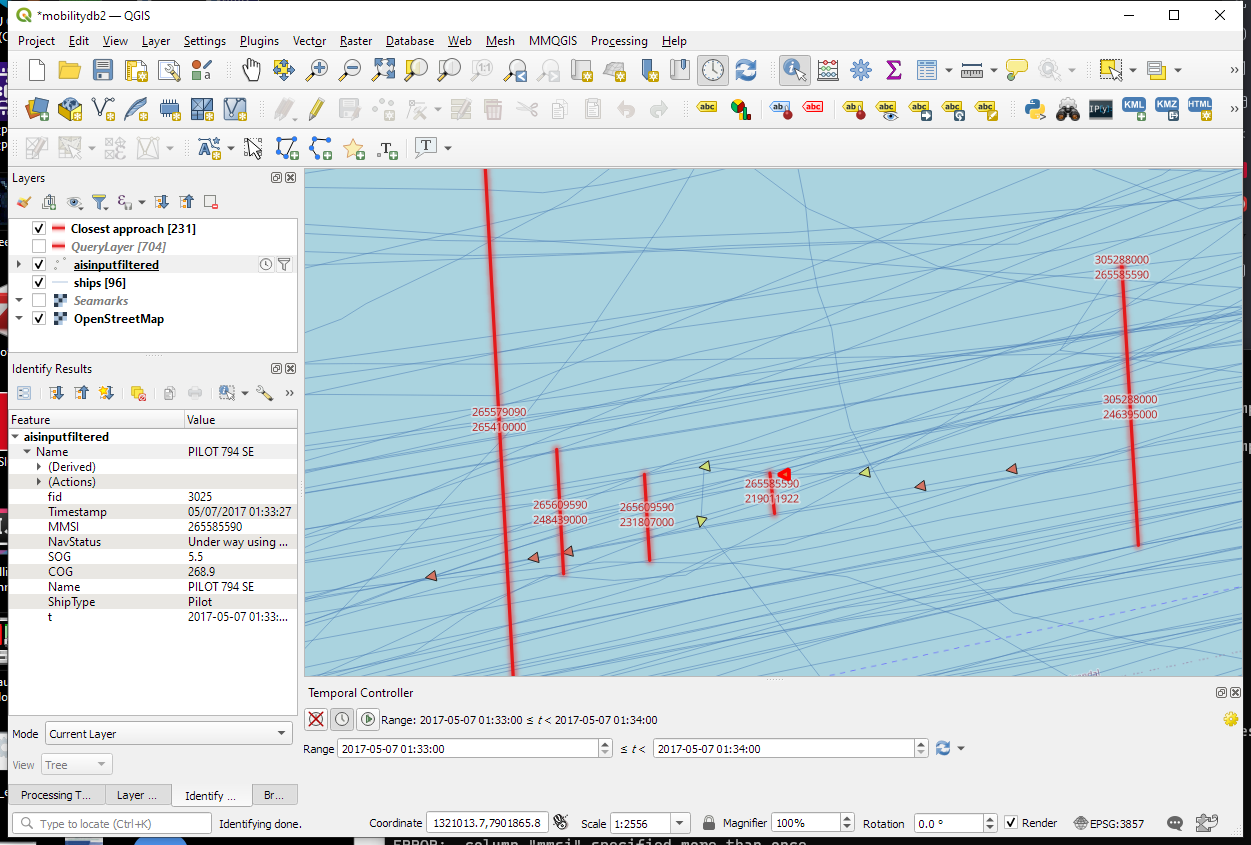
The resulting query layer shows where moving objects get close to each other:
To better see what’s going on, we’ll look at individual CPAs:
Having a closer look with the Temporal Controller
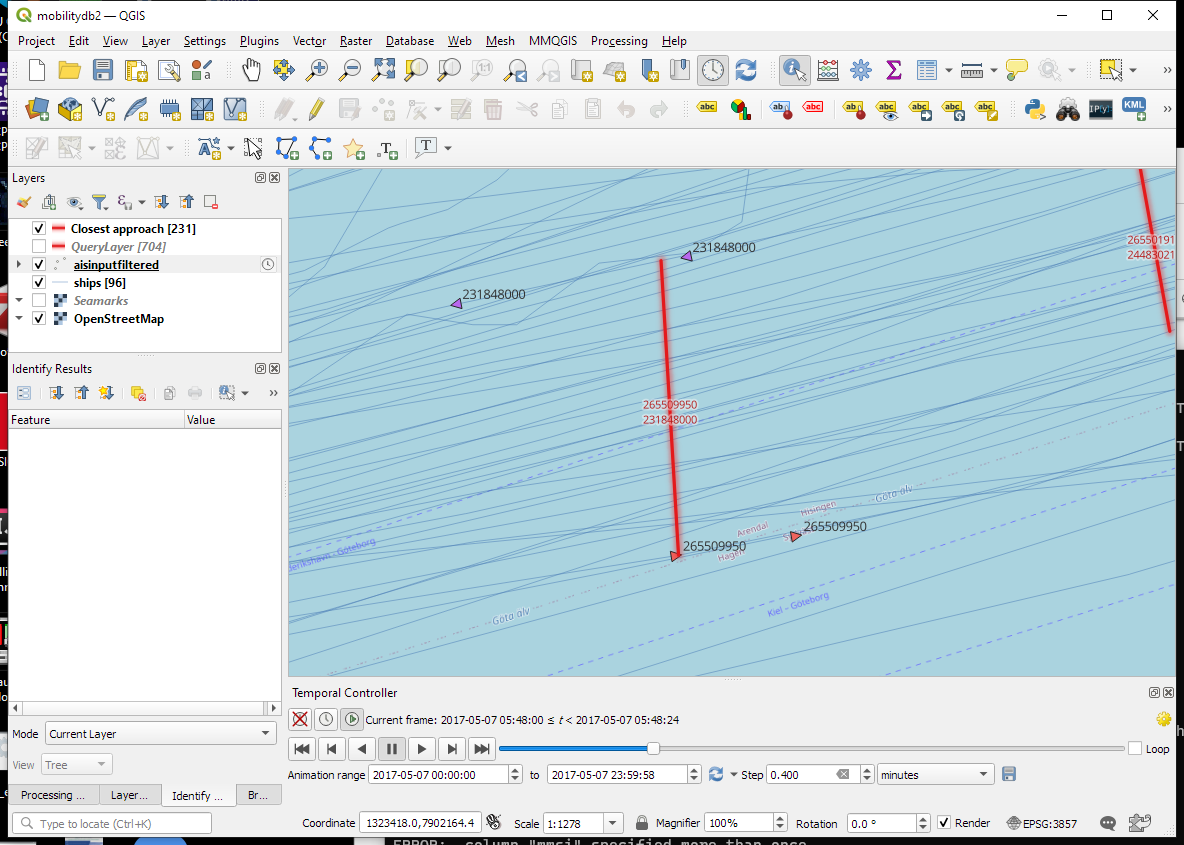
Since our filtered AIS layer has proper timestamps, we can animate it using the Temporal Controller. This enables us to replay the movement and see what was going on in a certain time frame.
I let the animation run and stopped it once I spotted a close encounter. Looking at the AIS points and the shortest line, we can see that MobilityDB computed the CPAs along the trajectories:
A more targeted way to investigate a specific CPA is to use the Temporal Controllers’ fixed temporal range mode to jump to a specific time frame. This is helpful if we already know the time frame we are interested in. For the CPA use case, this means that we can look up the timestamp of a nearby AIS position and set up the Temporal Controller accordingly:
More
I hope you enjoyed this quick dive into MobilityDB. For more details, including talks by the project founders, check out the project website.
Many of you certainly have already heard of and/or even used Leafmap by Qiusheng Wu.
Leafmap is a Python package for interactive spatial analysis with minimal coding in Jupyter environments. It provides interactive maps based on folium and ipyleaflet, spatial analysis functions using WhiteboxTools and whiteboxgui, and additional GUI elements based on ipywidgets.
This way, Leafmap achieves a look and feel that is reminiscent of a desktop GIS:
Recently, Qiusheng has started an additional project: the geospatial meta package which brings together a variety of different Python packages for geospatial analysis. As such, the main goals of geospatial are to make it easier to discover and use the diverse packages that make up the spatial Python ecosystem.
Besides the usual suspects, such as GeoPandas and of course Leafmap, one of the packages included in geospatial is MovingPandas. Thanks, Qiusheng!
I’ve tested the mamba install today and am very happy with how this worked out. There is just one small hiccup currently, which is related to an upstream jinja2 issue. After installing geospatial, I therefore downgraded jinja:
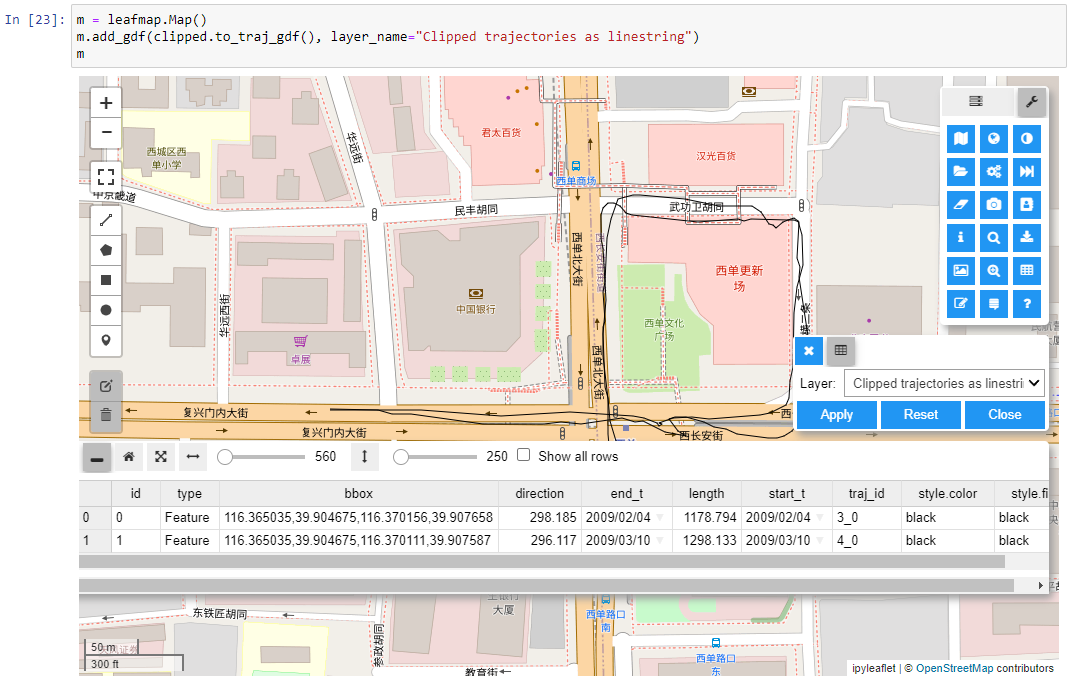
Of course, I had to try Leafmap and MovingPandas in action together. Therefore, I fired up one of the MovingPandas example notebook (here the example on clipping trajectories using polygons). As you can see, the integration is pretty smooth since Leafmap already support drawing GeoPandas GeoDataFrames and MovingPandas can convert trajectories to GeoDataFrames (both lines and points):
Clipped trajectory segments as linestrings in LeafmapLeafmap includes an attribute table view that can be activated on user request to show, e.g. trajectory informationAnd, of course, we can also map the original trajectory points
Geospatial also includes the new dask-geopandas library which I’m very much looking forward to trying out next.
MovingPandas 0.9rc3 has just been released, including important fixes for local coordinate support. Sports analytics is just one example of movement data analysis that uses local rather than geographic coordinates.
Many movement data sources – such as soccer players’ movements extracted from video footage – use local reference systems. This means that x and y represent positions within an arbitrary frame, such as a soccer field.
Since Geopandas and GeoViews support handling and plotting local coordinates just fine, there is nothing stopping us from applying all MovingPandas functionality to this data. For example, to visualize the movement speed of players:
Of course, we can also plot other trajectory attributes, such as the team affiliation.
But one particularly useful feature is the ability to use custom background images, for example, to show the soccer field layout:
Rendering large sets of trajectory lines gets messy fast. Different aggregation approaches have been developed to address this issue. However, most approaches, such as mobility graphs or generalized flow maps, cannot handle large input datasets. Building on M³ prototypes, the following approach can be used in distributed computing environments to extracts flows from large datasets.
This flow extraction is based on a two-step process, conceptually similar to Andrienko flow maps: first, we extract M³ prototypes from the movement data. In the second step, we determine flows between these prototypes, including information about: distribution of travel speeds and number of observed transitions. The resulting flows can be visualized, for example, to explore the popularity of different paths of movement:
Raw trajectory lines
Extracted flow map
After the prototypes have been computed, the flow algorithm computes transitions between pairs of prototypes. An object moving from prototype A to prototype B triggers an update of the corresponding flow. To allow for distributed processing, each node in the distributed computing environment needs a copy of the previously computed prototypes. Additionally, the raw movement data records need to be converted into trajectories. Afterwards, each trajectory is processed independently, going through its records in chronological order:
Find the best matching prototype for the current record
Ensure that the distance to the match is below the distance threshold and that the matched prototype is different from the previous prototype
Get or create the flow between the two prototypes
Ensure that the prototype and flow directions are a good match for the current record’s direction
Update the flow properties: travel speed and number of transitions, as well as the previous prototype reference
This approach scales to large datasets since only the prototypes, the (intermediate) flow results, and the trajectory currently being worked on have to be kept in memory for each iteration. However, this algorithm does not allow for continuous updates. Flows would have to be recomputed (at least locally) whenever prototypes changed. Therefore, the algorithm does not support exploration of continuous data streams. However, it can be used to explore large historical datasets: