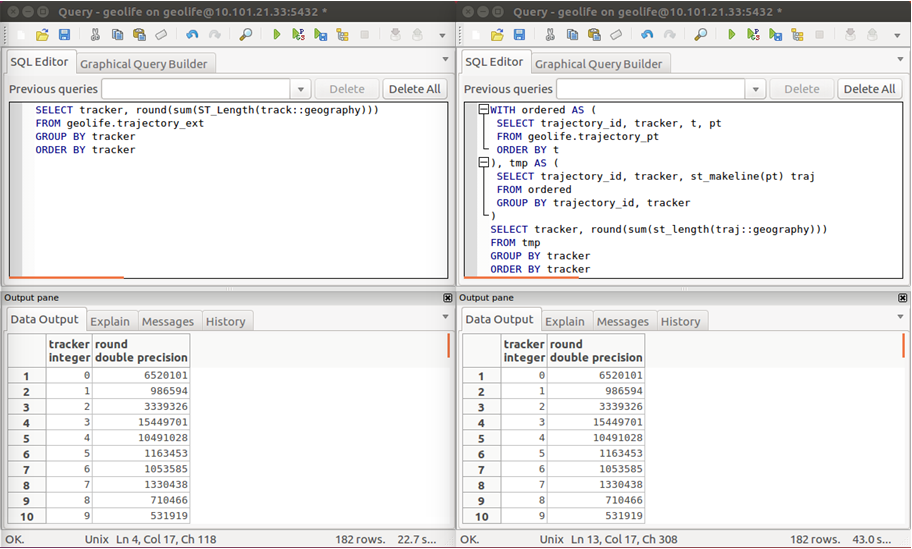
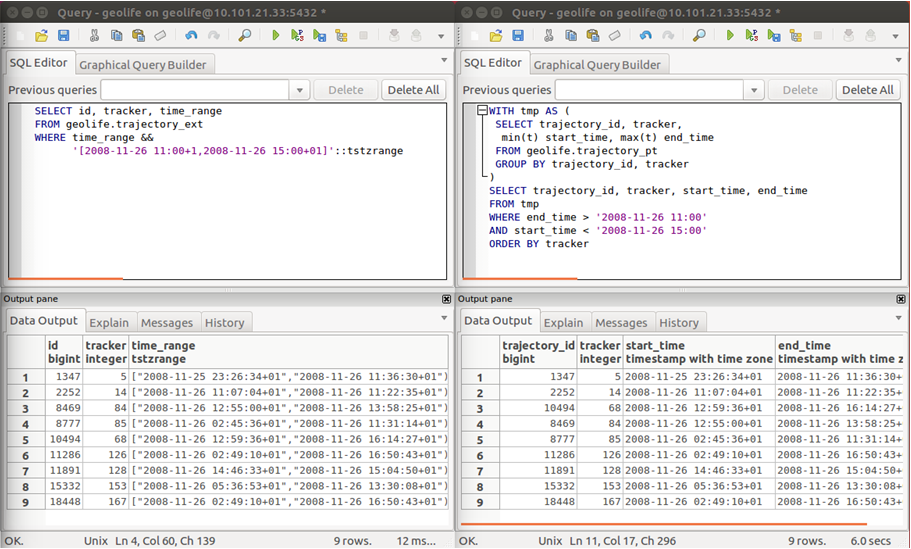
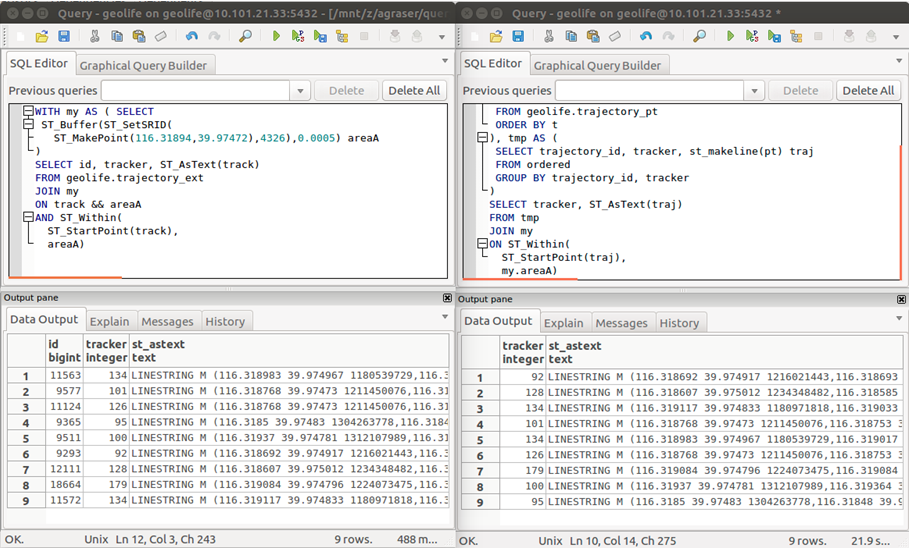
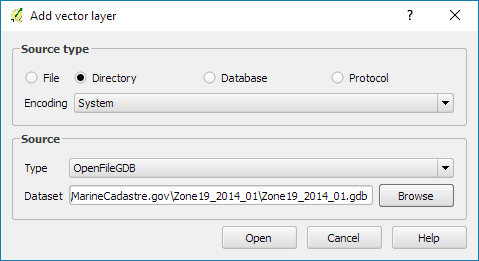
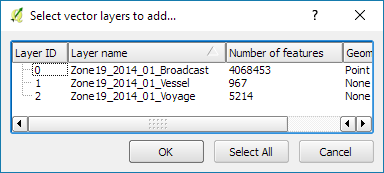
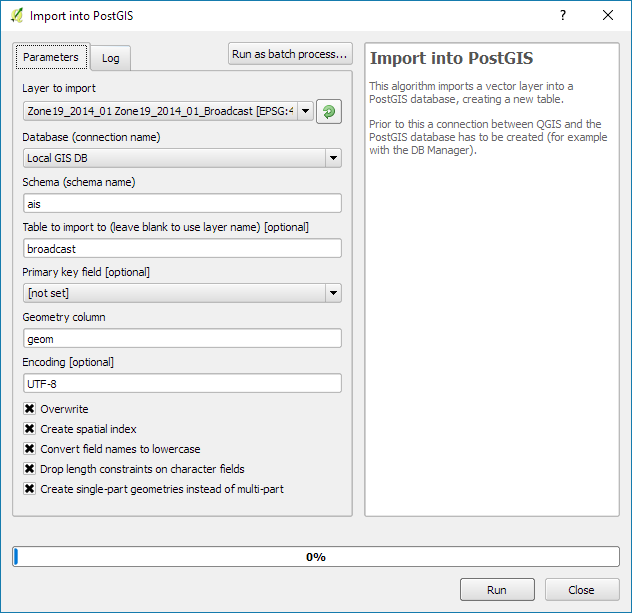
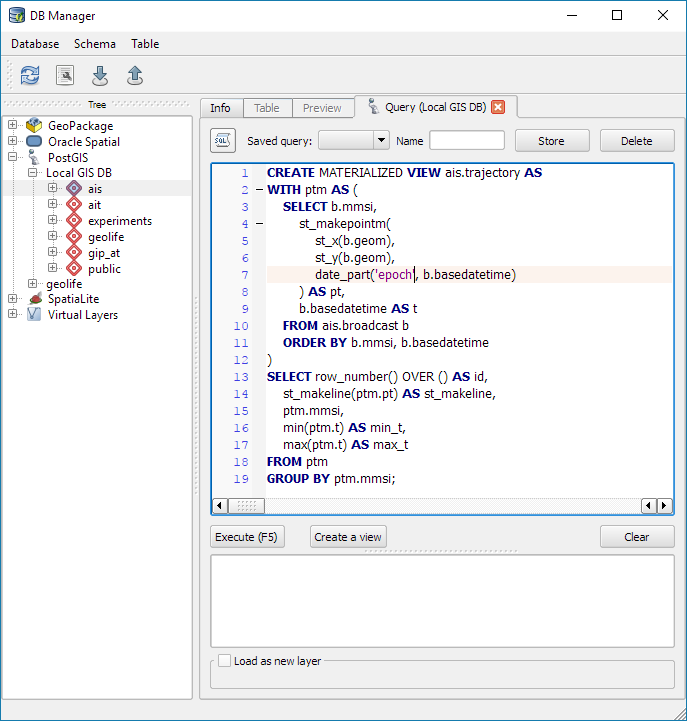
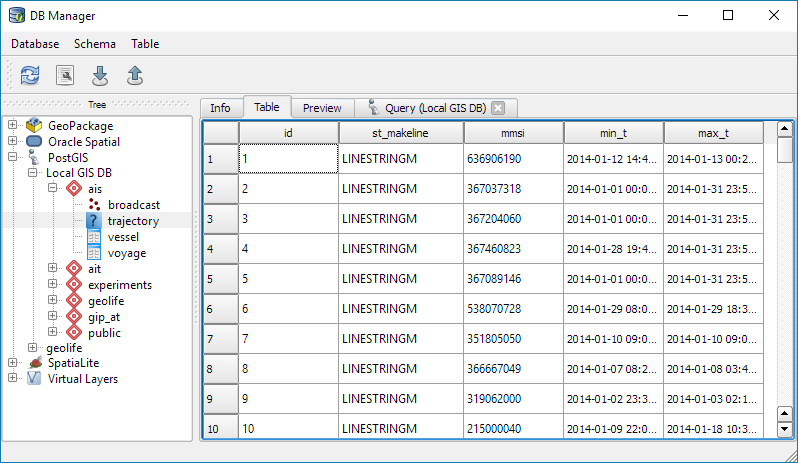
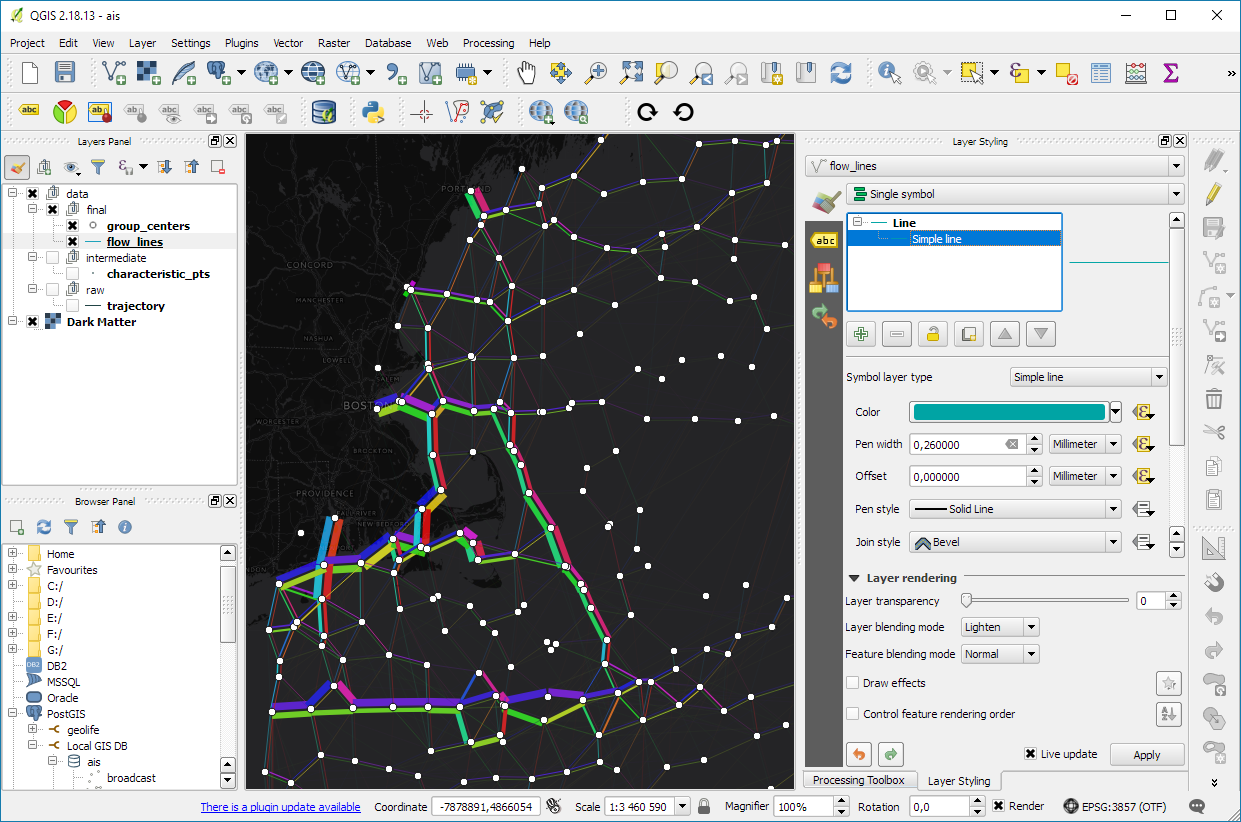
Recently there has been some buzz on Twitter about a new moving object database (MOD) called MobilityDB that builds on PostgreSQL and PostGIS (Zimányi et al. 2019). The MobilityDB Github repo has been published in February 2019 but according to the following presentation at PgConf.Russia 2019 it has been under development for a few years:
 Of course, moving object databases have been around for quite a while. The two most commonly cited MODs are HermesDB (Pelekis et al. 2008) which comes as an extension for either PostgreSQL or Oracle and is developed at the University of Piraeus and SECONDO (de Almeida et al. 2006) which is a stand-alone database system developed at the Fernuniversität Hagen. However, both MODs remain at the research prototype level and have not achieved broad adoption.
Of course, moving object databases have been around for quite a while. The two most commonly cited MODs are HermesDB (Pelekis et al. 2008) which comes as an extension for either PostgreSQL or Oracle and is developed at the University of Piraeus and SECONDO (de Almeida et al. 2006) which is a stand-alone database system developed at the Fernuniversität Hagen. However, both MODs remain at the research prototype level and have not achieved broad adoption.
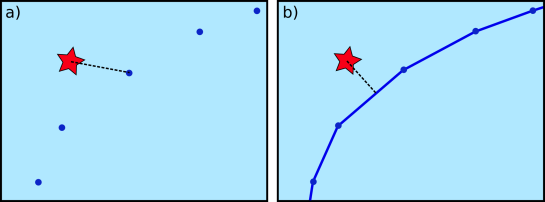
It will be interesting to see if MobilityDB will be able to achieve the goal they have set in the title of Zimányi et al. (2019) to become “a mainstream moving object database system”. It’s promising that they are building on PostGIS and using its mature spatial analysis functionality instead of reinventing the wheel. They also discuss why they decided that PostGIS trajectories (which I’ve written about in previous posts) are not the way to go:

However, the presentation does not go into detail whether there are any straightforward solutions to visualizing data stored in MobilityDB.
According to the Github readme, MobilityDB runs on Linux and needs PostGIS 2.5. They also provide an online demo as well as a Docker container with MobilityDB and all its dependencies. If you give it a try, I would love to hear about your experiences.

References
- de Almeida, V. T., Guting, R. H., & Behr, T. (2006). Querying moving objects in secondo. In 7th International Conference on Mobile Data Management (MDM’06) (pp. 47-47). IEEE.
- Pelekis, N., Frentzos, E., Giatrakos, N., & Theodoridis, Y. (2008). HERMES: aggregative LBS via a trajectory DB engine. In Proceedings of the 2008 ACM SIGMOD international conference on Management of data (pp. 1255-1258). ACM.
- Zimányi, E., Sakr, M., Lesuisse, A., & Bakli, M. (2019). MobilityDB: A Mainstream Moving Object Database System. In Proceedings of the 16th International Symposium on Spatial and Temporal Databases (pp. 206-209). ACM.
This post is part of a series. Read more about movement data in GIS.